9 Anvendelser af lineær algebra
9.1 Differentialligninger
Rutherfords og Soddys lov for radioaktivt henfald siger at en bestemt brøkdel af et grundstof vil henfalde per tidsenhed. Hvis vi med betegner antallet af atomer til tiden af grundstoffet, så kan loven skrives Ved at tidsintervallet går mod fås derfor differentialligningen som har løsningerne , hvor er en konstant, som er givet ved antallet af atomer til tiden i.e., . I mange anvendelser støder man på systemer af differentialligninger som hvor opgaven så går ud på at at finde funktioner , som opfylder (9.2). I (9.2) er koefficienterne konstanter (reelle tal).
Følgende eksempel er lånt fra Leons bog om anvendt lineær
algebra. Vi har to forbundne kar hver indeholdende L vand. Til
at begynde med indeholder det første kar gram salt og det andet
gram salt. Når hanerne tændes løber der vand gennem systemet som
indikeret nedenfor (per minut). Hanen, som tilfører L per minut,
indeholder ferskvand.
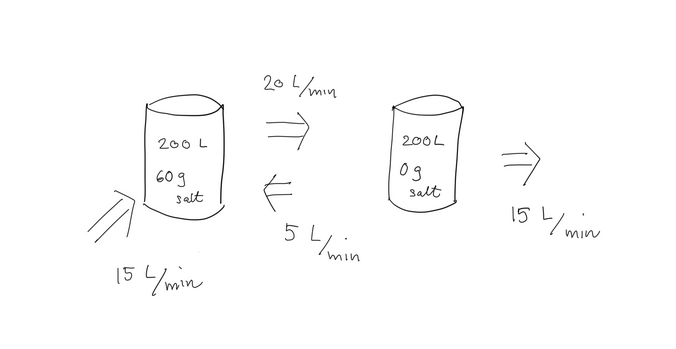 Hvad er indholdet af salt i de to beholdere til tiden ?
Her opstiller vi to funktioner og , som angiver
saltindhold (i gram) i hver beholder til tiden . Lad os sige at angiver saltindhold
i beholderen, som indeholder gram til at starte med. Ved at betrage et
lille tidsrum får vi ved almindelig købmandsregning:
som giver systemet
af differentialligninger med begyndelsesbetingelserne og .
Hvad er indholdet af salt i de to beholdere til tiden ?
Her opstiller vi to funktioner og , som angiver
saltindhold (i gram) i hver beholder til tiden . Lad os sige at angiver saltindhold
i beholderen, som indeholder gram til at starte med. Ved at betrage et
lille tidsrum får vi ved almindelig købmandsregning:
som giver systemet
af differentialligninger med begyndelsesbetingelserne og .
Hvad er indholdet af salt i de to beholdere til tiden ?
Her opstiller vi to funktioner og , som angiver
saltindhold (i gram) i hver beholder til tiden . Lad os sige at angiver saltindhold
i beholderen, som indeholder gram til at starte med. Ved at betrage et
lille tidsrum får vi ved almindelig købmandsregning:
som giver systemet
af differentialligninger med begyndelsesbetingelserne og .
9.1.1 Løsning via egenværdier og egenvektorer
Lad os kalde for en løsningsvektor til (9.2), hvis tilfredsstiller (9.2). Nedenstående siger at løsningsvektorerne minder om (er) et vektorrum.
Beviset følger ved direkte indsætning under brug af
Hvis er en egenværdi for og en egenvektor
hørende til , så er
en løsningsvektor til (9.2).
For har vi via (9.3) at
som ved division med netop giver det ønskede.
Hvis man i tilknytning til problemet om at løse (9.2) forlanger at
begyndelsesbetingelserne
skal være opfyldt, så findes kun en løsning med disse egenskaber for en given
vektor
Hvis har forskellige egenværdier med tilhørende
egenvektorer kan
denne løsning findes ved at bestemme konstanter så
Disse konstanter bestemmes ved at løse ligningssystemet
som skrevet ud bliver et ligningssystem med ligninger og ubekendte: .
Dette ligningssystem har en entydig løsning, da udgør en basis.
Lad os nu afprøve vores observationer på Eksempel 9.1. Matricen
har egenværdierne og med tilhørende egenvektorer
Via Proposition 9.3 og Proposition 9.2 er
derfor en løsningsvektor for vilkårlige . Med begyndelsesbetingelserne
og kan vi derfor bestemme konstanterne og ud fra
ligningssystemet
som har løsningerne og . De endelige løsninger bliver derfor
Efter en time er der kun gram salt i den første beholder () og
gram salt i den anden beholder ().
9.1.2 Oscillerende løsninger
Hvordan fortolkes en kompleks egenværdi og en tilhørende egenvektor for med hensyn til løsningen af differentialligningssystemet Det giver stadig god mening matematisk at sætte ind i (9.4) og se at ligningen er opfyldt, men her er en løsningsvektor med komplekse koordinater for . Lad os antage at og skrive med . Da har reelle indgange er invariant med hensyn til kompleks konjugering det vil sige . Derfor er også en egenværdi for med egenvektor , da Opdagelsen er at realdelen og imaginærdelen er løsninger til . Dette følger nemlig ud fra identiteterne ved at benytte Proposition 9.2. Real- og imaginærdelene kan udregnes via almindelig multiplikation af komplekse tal ud fra opspaltningen Her får man
Differentialligningen , hvor er en konstant, kan
ved et klassisk trick omskrives til
Her er differentialligningsystemet
og dermed er
med egenværdien og tilhørende egenvektor
Nu kan en løsning til den oprindelige differentialligning udregnes via (9.5) til
for passende konstanter .
9.2 Principal component analysis
Nedenstående anvendelse kommer fra kemi og er skrevet af Frank Jensen. Principal Component Analysis (PCA) er en hyppigt anvendt metode til at uddrage information fra store datamængder. Et eksempel er en computer simulering på et microsekund af et protein indeholdende atomer, hvor den rå datamængde er tidsmæssige adskilte positioner af atom koordinater. Langt størstedelen af denne information er tilfældige termiske bevægelser, som ikke er interessante, mens koordinerede atombevægelser, der ændrer proteinets struktur er interessante. Et andet eksempel er korrelationen mellem molekylers struktur og deres biologiske virkning, hvor et molekyles vekselvirkninger med det biologiske target kan kvantificeres ved dets egenskaber i f.eks. punkter i det -dimensionale rum omkring molekylet. I en Quantitative Structure Activity Relationship (QSAR) forsøger man at finde hvilke områder omkring et molekyle, der er vigtig for den biologiske virkning, ud fra informationen om hvordan de beskrivende variable for f.eks. molekyler korrelerer med deres biologiske aktivitet. Den rå information kan arrangeres i en rektangulær matrix , og vi er interesseret i korrelationen mellem elementerne i matricen. Dette kan vi finde ud fra en analyse af , som er en symmetrisk kvadratisk matrix. En sådan matrix kan ifølge noterne altid diagonaliseres ved en unitær transformation, hvor -matricen indeholder egenvektorerne.9.3 Spin
Kvantefysik er en ekstremt nøjagtig matematisk model. Den beskriver verden på partikel (eller felt) niveau, så vi er altså nede i det mest submikroskopiske. Teorien strider mod al sund fornuft, og den sunde fornuft taber altid kampen. I denne teori beskrives et fysisk systems tilstand som en vektor af længde 1 i et vektorrum med prikprodukt over de komplekse tal. Teorien kan forudsige hvad resultat af forskellige målinger kan give. De egenskaber som vi kan måle kaldes observable. Systemets position, hastighed, momentum, energi og så videre er alle eksempler på observable. Opskriften er at alle målinger vi kan udføre, altså alle observable, er repræsenterede af hermiteske matricer. Resultatet af en måling er en egenværdi af denne matrix. Hvis er et endeligt dimensionelt vektorrum er der altså kun endelig mange mulige resultater (hvorfor?)! Hvis vi i praksis udfører en måling på systemet forudsiger teorien ikke hvad for en egenværdi vi får ud af målingen, men giver kun sandsynligheder. Hvis tilstandsvektoren er en linearkombination af to egenvektorer og hørende til to forskellige egenværdier og for den hermiteske energioperator kunne teorien for eksempel forudsige ``med 33 procents sandsynlighed giver målingen af energien , og med 67 procents sandsynlighed giver målingen af energien ''. Disse sandsynligheder og kan beregnes med en simpel formel: For at gøre formlen endnu mere simpel plejer man at vælge eigenvektorer af længde 1, det vil sige så at de også er tilstandsfunktioner, og så at . Hvis man gør det er altså .
Vis at ! Der skal helt sikkert bruges at .
Dette lyder selvfølgelig som det rene nonsens, og I skal ikke have nogle illusioner om at det senere vil blive mindre underligt bare fordi man lærer mere om det, men det som teorien forudsiger er faktisk det man får ud af at gentage målingen mange gange og tælle op.
En beroligende bemærkning er at selv om de Hermiteske matricer har komplekse indgange, så giver disse målinger altid reelle tal, fordi vi har jo set at hvis er en hermitesk matrix, så er dens egenværdier relle. Det ville jo føles lidt uhyggeligt at sidde i et fly hvis piloten fortalte i speakeren at vi nu flyver i en højde af kilometer.
Nu kan man spørge: Hvis en partikels position er en observabel, hvordan kan det være at der kun er endeligt mange muligheder for en partikels position? Kan vi ikke flytte den meter i en bestemt retning, hvor er et vilkårligt reelt tal? Det fulde svar på dette spørgsmål er ret indviklet, men den korte version er at i dette tilfælde skal man betragte Hermiteske operatorer på vektorrum som ikke er af endelig dimension, det vil sige, der findes ikke en basis for vektorrummet der består af endeligt mange vektorer.
Nu til et konkret eksempel. Spin er en observabel som vi ikke kender fra den makroskopiske verden. Vi kan udføre følgende type måling. Den minder dog en del om impulsmoment, der fortæller noget om hvor hurtig noget roterer omkring en akse. Givet en enhedsvektor i rummet kan vi måle en partikels spin i denne retning ved at sende den gennem et passende magnetfelt, og se hvor meget den bliver afledet af magnetfeltet. Den sunde fornuft siger nu at denne afledning kan ske med et vinkel der variere kontinuert. Man det er ikke det der sker. Partiklen bliver afledet, enten opad eller nedad, med en bestemt konstant vinkel. Denne vinkel er given af partiklens ``spin'', som kan opfattes som en form for impulsmoment (angulært moment).
Dette var et af de tidlige eksperimenter (Stern-Gerlach, 1922) som viste nødvændigheden af at betragte kvantisering, i dette tilfælde en kvantisering af ``magnetisk impulsmoment'', som altså kun kan antage to værdier. I beskrivelsen af eksperimentet har jeg tilladt mig nogle hvide løgne og udeladelser for at koncentrere på det væsentlige.
Her er en model for dette fenomen.
Lad os sige at vi betragter en elektron.
Vi vil lave en måling af elektronens spin. For det første skal
vi vælge enhedsvektoren , . For at beregne partiklens spin i retning , skal vi bruge en hermitesk operator.
Elektronen har en indre struktur som er givet som en
tilstandsvektor
. Denne vektor betegnes som elektronens spin.
Observablen ``spin'' svarer til en bestemt hermitesk operator, men hvad for en?
Vi indfører de tre berømte Paulimatricer. De er komplekse matricer
Vis at de tre Paulimatricer er hermiteske matricer.
Vis at enhver hermitesk matrix kan skrives på en og kun en
måde som
hvor er relle tal og
Overvej om Paulimatricerne kommuterer, det vil sige hvorvidt for forskellige .
Det viser sig at den hermiteske operator som beregner det spin vi observerer i retningen er
Antag at . Vi antager at en elektronen er i en tilstand som beskrives ved vektoren
. Vi ønsker at beregne det forventede udfald af at måle elektronens spin i retning .
Ved et rent held er begge de to vektorer enhedsvektorer. Målingen vil altså resultere i en egenvektor til matricen
Det karakteristiske polynomium for er
Rødderne i det karakteristiske polynomium er og .
Der er altså kun to mulige resultater af målingen, nemlig . Lad os vedtage at
svarer til at spinnet er rettet langs , og til
at spinnet er rettet modsat . Denne vedtægt er i al væsentlighed et spørgsmål om
notation.
Vi finder tilhørende egenvektorer ved at løse ligninger:
er en egenvektor tilhørende egenværdi 1, og er en egenvektor hørende til egenværdi -1.
For en sikkerheds skyld laver vi prøve, som man altid skal.
og
Vi udtrykker nu i den ortogonale basis for der består af og .
Vektorerne er ikke enhedsvektorer, og kvadraterne på deres normer er
, .
Ved at løse ligninger finder vi at ,
og ,
Vi laver selvfølgelig prøve, fordi det gør man:
Modellen siger nu at sandsynligheden for at elektronens spin bliver målt til at være rettet langs
er
og at sandsynligheden for at spinnet bliver modsat mod er
.
Dem der synes at dette er alt for intuitivt og indlysende og har brug for
noget mere hjernefrysende anbefales at fortsætte studiet med
Bells ulighed.
9.4 En støtte vektor maskine
Artificiell intelligens er et stort område som bruger mange forskellige metoder. Nogle af de mest effektive af disse er inspireret fra biologi og neurologi, men vi vil ikke gå ind på den side af sagen. En almindelig forudsætning er at man har adgang til en meget stor database, og at hver enkelt element i denne database kan beskrives som en vektor i et vektorrum af meget høj dimension. Det er altså tale om en stor mængde af vektorer . Et eksempel ville for eksempel være en samling af billeder, repræsenterede ved farven i hver enkelt pixel. Opgaven er at foretage sig noget intelligent med denne meget store datamængde. Fordi data er givet ved vektorer er det ikke så forbavsende at lineær algebra næsten altid spiller en stor rolle. Som et eksempel som er blevet brugt i seriøse anvendelser, vil vi diskutere en ``support vector machine''. For en mere udførlig beskrivelse af matematikken bag dette anbefaler vi en forelæsning på MIT af Patrick Winston. Selv om man ikke er interesseret i matematikken er historien spændende, Winston fortæller den fra ca 46:19. For at forklare metoden vil vi arbejde med et konkret men lidt kunstigt eksempel. Antag at vi har en liste af byer, og at vi for hver by på listen kender dens longitud og lattitud og desuden ved hvad land byen ligger i. Opgaven er at skrive et program som helt automatisk kan placere en by som ikke er på vores liste i det rigtige land. For at gøre det simpelt antager vi at vi kun betragter to lande. I nogle situationer kunne det være nemt. For eksempel følger en stor del af grænsen mellem USA og Canada den 49ende parallel, så hvis vi kun interessere os for byer i dette område, kunne vi bruge funktionen . Hvis for en by med kordinater gælder at så ligger byen i USA, og hvis så er den i Canada. Mere generelt kunne man forestille sig lande med snorlige grænser som ikke nødvendigvis er longitud storcirkle eller latitud paraleller. Så kunne man finde en lineær funktion (med konstantterm ) så at betingelsen afgjorde en bys tilhørighedsforhold. Vi kan bruge vores liste af kendte byer til at finde gode vurderinger af . Som et lidt vanskeligere eksempel kan vi prøve at skelne byer i Danmark fra byer i Norge. Der er ikke en oplagt grænse mellem Danmark og Norge, men vi kan stadig lægge en linje gennem Skagerak der har Danmark på den ene side og Norge på den anden. Det kan vi også fortolke som en lineær funktion . Vi vil gerne vælge denne funktion så at den skelner mellem de to muligheder så godt som det er muligt. Vi vil ikke gå i detaljer med hvordan man finder denne funktion, men der eksisterer gode algoritmer som kan gøre det. De hører under noget der kaldes konveks optimering, som sådan set også bygger ovenpå lineær algebra. Man kan altså give listen med byer til en computer, og den producerer helt af sig selv en funktion sådan at hvis er koordinater for en af byerne på vores liste så er hvis og kun hvis den tilsvarende by er en by i Danmark. Og når vi har funktionen kan vi bruge den til at lave et rimeligt gæt på om en by med koordinater er i Danmark eller Norge. Dette gæt er nemlig afgjort af fortegnet af , og det virker lige så fint hvis vi har to mængder og i et Euklidisk run . Men forudsætningen er at de to mængder og rent faktisk kan skelnes ad ved en lineær afbildning Hvis det ikke kan lade sig gøre bliver algoritmen ved i det uendelige med at prøve på at løse et uløseligt problem. Men antag nu at vi er interesserede i byer der ligger enten i Sverige eller i Danmark. Selv om de to lande er skilt fra hinanden af Øresunds og Kattegats vande er det umuligt at skelne dem ad med en lineær funktion . Specielt er Bornholm problematisk. Vi kan altså ikke bruge den gode algoritme. Men vi kan gøre noget andet. Vi finder en ikke-lineær afbinding . For eksempel kunne vi vælge , eller skrevet på matrix form .
Vis at med det vi har valgt ovenfor er
.
Selv om vi ikke kan skelne mængden fra med en lineær afbildning, så kan vi måske skelne deres billeder og fra hinanden med en lineær afbildning. En pointe er nu at det væsentlige input i den fine algoritme som kan finde en lineær afbildning der skelner fra er netop de indre produkter . Så hvis vi kan skelne fra med en lineær afbildning, og hvis kan angive en formel for de indre produkter så kan algoritmen fortælle os nøjagtig hvad for et vi skal bruge. Det vil sige, hvis er en af vores byer så er i Danmark hvis og i Sverige hvis
.
Antag nu at for eksempel er koordinaterne for Hesselø. Selv om Hesselø (Hesselö) ikke er på vores liste af kendte byer , kan vi lave det rimelige gæt at hvis
så hører Hesselø til Danmark. Vi kan selvfølgelig ikke vide det helt sikkert.
Lad og . Overvej at
man ikke kan finde reelle tal så at hvis så er
og hvis så er .
Find reelle tal sådanne at hvis
så er
men hvis
så er