4 Matricer
Kommentarer/spørgsmål?
Når man har regnet med lineære ligninger et stykke tid opstår behovet
for at forenkle notationen. For eksempel kan
ligningerne
repræsenteres ved talskemaet
og mange af de operationer vi foretager for at løse ligningerne kan lige så vel udføres på det tilsvarende talskema.
4.1 Matricer
4.1.1 Definitioner
Et rektangulært talskema kaldes en matrix. En matrix med rækker og søjler kaldes en (læs: gange ) matrix. Notation for en matrix er hvor betegner tallet i -te række og -te søjle. Hvis vi kalder matricen i (4.2) for , består den af rækker og søjler med .- En matrix kaldes kvadratisk hvis den har lige så mange rækker som søjler. For eksempel er de første to matricer nedenfor kvadratiske, mens den tredje ikke er det.
- Diagonalen i en matrix er defineret som indgangene i matricen med samme række- og søjlenummer. Nedenfor er angivet en matrix, hvor diagonalelementerne er markerede En matrix kaldes en diagonalmatrix, hvis alle dens indgange udenfor diagonalen er . Nedenfor er et eksempel på en kvadratisk diagonalmatrix
- En matrix kaldes en rækkevektor hvis den kun har en række. For eksempel er en rækkevektor med tre søjler.
- En matrix kaldes en søjlevektor hvis den kun har en søjle. For eksempel er en søjlevektor med tre rækker.
- Rækkerne i en matrix kaldes matricens rækkevektorer. Den -række i en matrix betegnes . For eksempel har matricen i (4.2) rækkevektorerne
- Søjlerne i en matrix kaldes matricens søjlevektorer. Den -te søjle i en matrix betegnes . For eksempel har matricen i (4.2) søjlevektorerne
- En række- eller søjlevektor refereres til som en vektor.
4.2 Matrixmultiplikation
Antag vi har givet to ligningssystemer i de variable og . Vi får et nyt ligningssystem i og ved at sætte og ind i det første ligningssystem: Med matricer skriver vi Lad os prøve at skrive operationen i (4.4) ud generelt det vil sige antag vi har to ligningssystemer a la ovenfor: men nu med generelle koefficienter. Ved substitution fås som før som så er lig med Formuleret med matricer som i (4.4) skrives Ligningen ovenfor er intet mindre end formlen for multiplikation af to matricer, præcis som den blev indført historisk af Cayley omkring 1857. Ved nærmere eftersyn (og markeret med farver i (4.5) for og ) ses reglen at tallet i den -te række og -te søjle i produktmatricen er række-søjle multiplikationen mellem -te række og -te søjle i de to matricer.
Rækkesøjle multiplikationen mellem en rækkevektor
og en søjlevektor
med det samme antal indgange er defineret som
Hvis man er lidt pedantisk vil man måske i notationen skelne mellem tallet og matricen , men det er vi ikke.
Lad være en matrix og en matrix. Så er produktet defineret som matricen givet ved
for og .
Hvis er en matrix og en matrix giver matrixproduktet kun mening,
hvis : Antallet af søjler i skal være lig med antallet af rækker i .
Lad matricerne
være givet. Hvilke af nedenstående matrixprodukter giver mening?
Kommentarer/spørgsmål?
Med formlen for matrix multiplikation kan ligningssystemet (4.1) nu skrives som
Her ganger vi en matrix sammen med en
matrix. Rækkesøjlemultiplikationen giver matricen
Denne matrix skal netop være lig med matricen på
højresiden ovenfor for at ligningssystemet (4.1) er opfyldt.
Lad
Hvilke af nedenstående udsagn er rigtige?
Hvis , så er .
Hvis , så er .
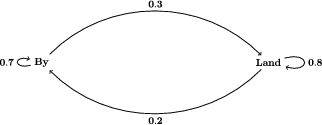
Matrixmultiplikation forekommer naturligt i sandsynlighedsregning. Lad os illustrere med et enkelt eksempel.
Lad os antage at rundt regnet af de mennesker, der bor på landet, flytter til byen og at
af de mennesker, som bor i byen flytter til landet. Lad os også fastslå at disse procentsatser er opgjort per år og lige omformulere en smule:
 Dette giver anledning til lidt købmandsregning. Lad os sige at der i
starten til tiden år bor mennesker i byen og
mennesker på landet. Hvor mange mennesker bor der så i byen og hvor mange mennesker bor der på landet til tiden år?
Med ord bliver byen affolket med , men der kommer tilflyttere,
som udgør af befolkningen på landet. Det vil sige
Tilsvarende har vi for befolkningen på landet at
Dette kan skrives via matrixmultiplikation som
Proceduren giver også mening for år. Her bliver resultatet
hvor
Ovenstående kan generaliseres så vi har formlen
som giver fordelingen af by- og landbefolkning til tiden
år. For at kunne benytte formlen (4.8) skal vi altså
udføre matrixmultiplikationer, hvilket kan være lidt
overvældende, for eksempel hvis vi ønsker at kende befolkningstallet på landet
efter år. Hver matrixmultiplikation indeholder almindelige
talmultiplikationer og almindelige taladditioner. Vi vil senere i kapitlet se hvordan egenvektorer og egenværdier for
matricer kan hjælpe med denne udregning.
Inden da, lad os blot eksperimentere med at udregne de første potenser af :
Umiddelbart ser det ud som om udregningerne stabiliseres på et
stationært niveau, hvor bor i byen og på landet taget ud
fra det samlede indbyggertal til at begynde med det vil sige til år.
Matricen er et eksempel på en stokastisk matrix.
Generelt kaldes en kvadratisk matrix en stokastisk matrix hvis alle
dens indgange er og dens søjlesummer er .
Dette giver anledning til lidt købmandsregning. Lad os sige at der i
starten til tiden år bor mennesker i byen og
mennesker på landet. Hvor mange mennesker bor der så i byen og hvor mange mennesker bor der på landet til tiden år?
Med ord bliver byen affolket med , men der kommer tilflyttere,
som udgør af befolkningen på landet. Det vil sige
Tilsvarende har vi for befolkningen på landet at
Dette kan skrives via matrixmultiplikation som
Proceduren giver også mening for år. Her bliver resultatet
hvor
Ovenstående kan generaliseres så vi har formlen
som giver fordelingen af by- og landbefolkning til tiden
år. For at kunne benytte formlen (4.8) skal vi altså
udføre matrixmultiplikationer, hvilket kan være lidt
overvældende, for eksempel hvis vi ønsker at kende befolkningstallet på landet
efter år. Hver matrixmultiplikation indeholder almindelige
talmultiplikationer og almindelige taladditioner. Vi vil senere i kapitlet se hvordan egenvektorer og egenværdier for
matricer kan hjælpe med denne udregning.
Inden da, lad os blot eksperimentere med at udregne de første potenser af :
Umiddelbart ser det ud som om udregningerne stabiliseres på et
stationært niveau, hvor bor i byen og på landet taget ud
fra det samlede indbyggertal til at begynde med det vil sige til år.
Matricen er et eksempel på en stokastisk matrix.
Generelt kaldes en kvadratisk matrix en stokastisk matrix hvis alle
dens indgange er og dens søjlesummer er .
Nedenfor et eksempel på anvendelser i netværksteori.
- Hvis man bor på landet er sandsynligheden for at man flytter til byen ,
- Hvis man bor på landet er sandsynligheden for at man bliver boende ,
- Hvis man bor i byen er sandsynligheden for at man flytter til landet ,
- Hvis man bor i byen er sandsynligheden for at man bliver boende ,
Dette giver anledning til lidt købmandsregning. Lad os sige at der i
starten til tiden år bor mennesker i byen og
mennesker på landet. Hvor mange mennesker bor der så i byen og hvor mange mennesker bor der på landet til tiden år?
Med ord bliver byen affolket med , men der kommer tilflyttere,
som udgør af befolkningen på landet. Det vil sige
Tilsvarende har vi for befolkningen på landet at
Dette kan skrives via matrixmultiplikation som
Proceduren giver også mening for år. Her bliver resultatet
hvor
Ovenstående kan generaliseres så vi har formlen
Matrixmultiplikation forekommer også i praktiske problemer, hvor
netværk er involveret. Lad os antage vi har fem byer, som er
forbundet med forskellige veje som nedenfor
 Dette netværk har en incidensmatrix, hvor by nummer hører til
-te række og -te søjle. Et -tal i matricen på plads betyder at der er en
vej fra by til by , mens et betyder at by og by ikke er forbundet med en vej:
Her er
Hvad er netværksfortolkningen af og generelt ? Det
viser sig at fortolkningen af indgang i matricen netop
er antallet af stier af længde fra by til by . For eksempel
ser vi ovenfor at der er stier fra by til by af længde
svarende til . De stier fra by til by af
længde er og de stier af længde fra by til
er .
Lad os antage at vi har et netværk med byer og en tilhørende incidensmatrix .
Det generelle bevis bygger på at
en sti af længde fra by til by må ende med en vej fra en
naboby til . For hver af disse nabobyer kan vi så nøjes med at
tælle antallet af stier af længde fra by .
Hvis vi nu antager at er antallet af
stier af længde fra by til by , så siger matrixmultiplikation at
Dette tal er antallet af stier af længde fra by til by fordi
netop når er en naboby til (og ellers ).
Dette netværk har en incidensmatrix, hvor by nummer hører til
-te række og -te søjle. Et -tal i matricen på plads betyder at der er en
vej fra by til by , mens et betyder at by og by ikke er forbundet med en vej:
Her er
Hvad er netværksfortolkningen af og generelt ? Det
viser sig at fortolkningen af indgang i matricen netop
er antallet af stier af længde fra by til by . For eksempel
ser vi ovenfor at der er stier fra by til by af længde
svarende til . De stier fra by til by af
længde er og de stier af længde fra by til
er .
Lad os antage at vi har et netværk med byer og en tilhørende incidensmatrix .
Det generelle bevis bygger på at
en sti af længde fra by til by må ende med en vej fra en
naboby til . For hver af disse nabobyer kan vi så nøjes med at
tælle antallet af stier af længde fra by .
Hvis vi nu antager at er antallet af
stier af længde fra by til by , så siger matrixmultiplikation at
Dette tal er antallet af stier af længde fra by til by fordi
netop når er en naboby til (og ellers ).
Dette netværk har en incidensmatrix, hvor by nummer hører til
-te række og -te søjle. Et -tal i matricen på plads betyder at der er en
vej fra by til by , mens et betyder at by og by ikke er forbundet med en vej:
Her er
Hvad er netværksfortolkningen af og generelt ? Det
viser sig at fortolkningen af indgang i matricen netop
er antallet af stier af længde fra by til by . For eksempel
ser vi ovenfor at der er stier fra by til by af længde
svarende til . De stier fra by til by af
længde er og de stier af længde fra by til
er .
Lad os antage at vi har et netværk med byer og en tilhørende incidensmatrix .
Det generelle bevis bygger på at
en sti af længde fra by til by må ende med en vej fra en
naboby til . For hver af disse nabobyer kan vi så nøjes med at
tælle antallet af stier af længde fra by .
Hvis vi nu antager at er antallet af
stier af længde fra by til by , så siger matrixmultiplikation at
Dette tal er antallet af stier af længde fra by til by fordi
netop når er en naboby til (og ellers ).
4.3 Matrixregning
Matrixmultiplikation er forskellig fra almindelig talmultiplikation på et helt centralt punkt: Faktorernes orden er ikke ligegyldig. Betragt matricerne Så er dvs . Man siger også at matrixmultiplikation er ikke-kommutativ.4.3.1 Addition af matricer
Man kan (næsten) regne med matricer som almindelige tal. Specielt giver det mening at lægge matricer med samme antal rækker og søjler sammen indgang for indgang: Med hensyn til addition opfører matricer sig ligesom almindelige tal, det vil sige at .4.3.2 Skalarmultiplikation af matricer
En matrix kan på naturlig måde multipliceres med et tal ved at gange ind plads for plads:
Findes et tal så
4.3.3 Den distributive lov
For almindelige tal gælder at man kan gange ind i en parentes det vil sige . Denne regel gælder også for matricer og kaldes generelt for den distributive lov (gange bliver distribueret (fordelt) over plus).
Lad og være matricer, en matrix og en matrix. Så gælder
Man kan nøjes med at bevise den første påstand i tilfældet, hvor er en rækkevektor og
søjlevektorer, fordi
Tilsvarende kan den anden påstand bevises i tilfældet hvor
er rækkevektorer og en søjlevektor, fordi
Begge disse tilfælde følger af den distributive lov for almindelige tal.
For eksempel, hvis er en rækkevektor og
søjlevektorer, så er
og begge matricer, det vil sige at de kun har et eneste element. Helt præcis er
4.3.4 Den mirakuløse associative lov
Giver det mening at gange tre matricer og sammen? Vi har faktisk kun defineret produktet af to matricer. Der er to naturlige måder at udregne produktet på: Vi kan begynde med at gange sammen med og så gange på fra højre. Vi kan også først gange sammen med og så gange på fra venstre. Det er slet ikke klart at de to måder leder frem til samme resultat! At det gælder er helt centralt når man regner med matricer. Resultatet kaldes den associative lov for matrixmultiplikation.
Lad være en matrix, en matrix og en matrix. Så er
Det nedenstående bevis er ikke særlig informativt, men det er korrekt.
Senere, når vi har set
sammenhængen mellem matricer og lineære afbildninger, vil vi være i stand til at give en meget bedre forklaring på hvorfor den associative lov er en selvfølge.
Vi skal bevise at
for og . Venstresiden kan skrives
Højresiden kan skrives som
Ved at skrive rækkesøjle multiplikationerne i (4.9) ud fås
Ved at skrive rækkesøjle multiplikationerne i (4.10) ud fås
Rækkerne i summen i (4.11) svarer til søjlerne i summen (4.12) og det ses at
disse summer er ens. Derfor er .
4.3.5 Opbygning af matricer fra søjler
Hvis vi har søjlevektorer som alle har højde kan vi danne en matrix ved at sætte dem ved siden af hinanden. Så hvis vi har søjlevektorerne så er Vi kan genfinde søjlevektorerne af som ,, og . Vi vil senere få brug for følgende simple udregning.
Hvis er en matrix, så er
Vi regner efter. På den ene side er
På den anden side er
Illustration af beviset ved et eksempel
Nu er
4.3.6 Identitetsmatricen
Identitetsmatricen af orden er diagonalmatricen med i diagonalen. Nedenfor er identitetsmatricen af orden Identitetsmatricen har egenskaben at for alle matricer .
Gør rede for ovenstående egenskab det vil sige at identitetsmatricen ikke ændrer ved en kvadratisk matrix når den bliver ganget på enten fra venstre eller fra højre.
4.3.7 Den inverse matrix
Man kan dividere med almindelige tal . Giver det mening at dividere med matricer? Et almindeligt tal har et "inverst" tal så . Her kan vi bare sætte . Vi kan umiddelbart overføre denne definition til kvadratiske matricer.
Lad og være matricer. Gør rede for at hvis
og
så må .
En matrix siges at være invertibel, hvis der eksisterer en matrix så
I givet fald kaldes den inverse matrix og betegnes .
Man kunne jo spørge om det kan ske for en matrix hvor at
der findes en matrix så at . Det
kan desværre aldrig lade sig gøre, selv om det sagtens kan ske at der findes en
matrix så at .
Kommentarer/spørgsmål?
Den inverse matrix kommer for eksempel ind i billedet ved løsning af lineære
ligninger. Et lineært ligningssystem med ligninger og
ubekendte:
kan med matrixnotation skrives
eller mere kompakt som .
Hvis er invertibel giver den associative lov følgende udregning:
Ligningssystemet
kan ved hjælp af matrixmultiplikation skrives som
hvor
Jeg kan her afsløre at rent faktisk er invertibel samt at
En enkel matrixmultiplikation:
afslører som forventet løsningen til ligningssystemet i (4.13).
Produktet af to invertible matricer (når produktet giver mening) er
også en invertibel matrix. Dette er indholdet af følgende resultat,
som bevises helt formelt ud fra definitionen og den associative lov.
Produktet af to invertible matricer og er invertibelt med
.
Vi skal checke betingelserne i definitionen det vil sige at
Lad os checke den første betingelse ved brug af den associative lov:
hvor betegner identitetsmatricen. Betingelsen checkes analogt.
4.3.8 Den transponerede matrix
Den transponerede til en matrix er matricen givet ved det vil sige matricen, som indeholder søjlerne i som rækker (og rækkerne som søjler). For eksempel er Læg også mærke til at for en vilkårlig matrix .
Lad være en matrix og en matrix. Så er
Per definition er . Denne indgang er
givet som række-søjle multiplikation mellem -te række i og
-te søjle i , hvilket er identisk med række-søjle multiplikation mellem
-række i og -te søjle i .
Lad være en kvadratisk matrix. Gør rede for at er invertibel hvis og kun hvis
er invertibel.
En kvadratisk matrix kaldes symmetrisk hvis . Gør rede for at
er en symmetrisk matrix, hvor er en vilkårlig matrix.
Brug proposition 4.16!
4.4 Rækkeoperationer
Der er en række meget naturlige operationer man kan udføre på matricer, som præcis svarer til hvad man ville gøre på det tilsvarende system af ligninger:- Ombytning af to rækker.
- Multiplikation af en række med et tal forskellig fra nul.
- Addition af en række multipliceret med et tal til en anden række.
To matricer og kaldes rækkeækvivalente, hvis man kan udføre en følge af
rækkeoperationer på og få frem. Dette skrives .
Betragt følgende fire matricer
Hvilke af følgende udsagn er sande?
Lad , og være tre matricer med samme antal rækker og søjler. Gør rede for at
- .
- medfører at .
- medfører at .
Vis at hvis så er , det vil sige, hvis at man kan udføre en følge af rækkeoperationer på så at man ender med at få frem.
Operationen () svarer til Gauss elimination. At trække første ligning fra anden ligning i (4.1) svarer til at gange første række i (4.2) med og addere til anden række. Efter denne operation på matricen (4.2) har vi matricen
Vi benytter nu operationen () og ganger anden række med og får matricen
Tilsvarende ganger vi første række med og får matricen
Hvis vi omformulerer matricen ovenfor til ligninger, svarer den til
Intuitivt er rækkefølgen af ligningerne her forkert. Vi vil gerne have at ligningen indeholdende den første variabel kommer først. Vi benytter operationen () og bytter rundt på første og anden række. Dermed har vi
Vi accepterer matricen til sidst i (4.15) som en specielt enkel form vi kan reducere den oprindelige matrix (4.2) til. Den enkle form af matricen afspejler sig i det tilsvarende ligningssystem ved at man umiddelbart kan aflæse løsningerne til at være
Det Vil Sige er en fri variabel og bestemmer og som ovenfor.
Den simple form vi har reduceret den oprindelige matrix til kaldes reduceret række echelon form.
4.5 Reduceret række echelon form (RREF)
En række i en matrix kaldes en nulrække hvis alle dens indgange er tallet .
En matrix siges at være på reduceret række echelon form (RREF) hvis
- Nulrækker er i bunden af matricen.
- Hvis en række i ikke er en nulrække, så er den første indgang i rækken tallet . Denne indgang kaldes et pivotelement.
- Et pivotelement er længere til højre end pivotelementerne i de foregående rækker.
- Et pivotelement er den eneste indgang i sin søjle.
Hvilke af nedenstående matricer er på RREF?
Enhver matrix er rækkeækvivalent med en entydig matrix på RREF.
Stop! Hvorfor kan vi antage det?
Jo, fordi hvis vi tilsvarende sletter de sidste søjler i og får vi to
matricer og . Og og er begge RREF for .
Ifølge vores induktionsantagelse er dermed .
og kan kun adskille i den sidste
søjle, så vores opgave er at vise at også de to sidste søjler er ens, det vil sige at .
Vi skelner nu mellem to tilfælder. Det første tilfælde er at
både og er pivotsøjler. Det andet tilfælde er at
enten ikke er en pivotsøjle i , eller at ikke er en pivotsøjle i . Vi giver et argument der viser at i det første tilfælde, og et helt andet argument der viser at i det andet tilfælde. Tilsammen beviser de to argumenter sætningen.
Bevis for at B og C er ens i det første tilfælde
Antag at og begge er pivotsøjler.
Vi kigger først på . Vi bemærker at pivotsøjlen er
bestemt af . Hvis vi kender og ved at den sidste søjle er en pivotsøjle, så kender vi også .
Pivotelementet står nemlig i den første række i der er en nullrække i .
På den samme måde er bestemt af , fordi vi ved at er en pivotsøjle. Men da følger det at .
Bevis for at B og C er ens i det andet tilfælde
Enten er den sidste række i eller den sidste række i ikke en pivotsøjle. Der er ikke forskel på og i antagelserne, så
vi kan også lige så godt antage at det er der ikke er en pivotsøjle. Det efterfølgende argument virker lige så fint for , vi skifter bare ud mod i notationen.
Vi antager altså at ikke er en pivotsøjle.
Da den sidste række i ikke er en pivotsøjle, kan vi finde ifølge bemærkning 4.27 finde en løsning til vektorligningen som opfylder at .
Nu er og RREF til den samme matrix , så hvis
er også og , og dermed .
Siden befinder sig de eneste elementer i der er forskellige fra 0 i den sidste søjle. Hvis vi tager højde for dette og udfører matrixmultiplikationen får vi
Her er en matrix. Da har vi lov til at dividere med . Vi får at , og dermed er vi færdige.
Et eksempel til illustration af proceduren i beviset kunne være
hvor .
Her er
og dermed
Derfor bliver
og de markerede pivotelementer ovenfor bruges ved Gauss elimination til at give den endelige RREF
4.5.1 Løsning af ligninger ved hjælp af RREF
Hvis en matrix er på RREF er ligningssystemet med ligninger og variable specielt nemt at gå til. Pivotelementerne i er de eneste indgange i deres søjle . Deres søjlenumre svarer til de såkaldte bundne variable. De øvrige søjlenumre svarer til de såkaldte frie variable. Vi samler de frie variable i en vektor , og de bundne variable i en anden vektor . Lad os se på et konkret eksempel. Lad Da er på RREF, og de tre pivoter står i søjlerne med nummer . Hvis vi vil løse en ligning , så er , de bundne variable er og de frie variable er . Vi skriver altså og . Vi laver nu en lille omsortering af søjlerne i . Vi flytter de tre pivot søjle foran. De resterende søjler der svarer til bundne variable samler vi til en matrix vi kalder Nu ser vi at følgende to ligninger er fuldstændigt ensbetydende: Formuleret i matrixsprog siger det at ligningen er ensbetydende med at som er ensbetydende med at For eksempel er en løsning til hvis og kun hvis Her er de bundne variable og de frie variable. Skrevet som ligninger svarer dette til ligningssystemet med løsningsformlerne Læg mærke til at er en fri variabel, som her ikke indgår i formlerne for .
Det betyder, for eksempel, at hvis er en matrix på RREF, og hvis en søjle i matricen med søjlenummer ikke indeholder en pivot, så findes der en søjlevektor så at hver indgang i opfylder at , og desuden sådan at .
Vi har allerede brugt denne bemærkning i beviset for
den vigtige sætning (4.25). Men måske var det snyd at vi brugte et resultat der står senere i teksten? Lidt som at rejse tilbage i tiden og give sig selv de rigtige lottotal? Argumentér for at vi ikke har snydt (eller argumentér alternativt for at vi har snydt).
Kommentarer/spørgsmål?
4.6 Elementære matricer
Vi vil nu omfortolke rækkeoperationer ved hjælp af matrixmultiplikation. Hver af de tre typer af rækkeoperationer som vi beskrev i begyndelsen af 4.4 svarer til multiplikation fra venstre med en matrix af en bestemt type. For eksempel er ombytning af rækkke 1 med række 2 i en matrix det samme som multiplikation fra venstre med Multiplikation af den anden række med 5 er detsamme som produkt med og operationen at gange den tredie række med og lægge den til den første række er detsamme som multiplikation med matricen
For eksempel giver udtrykket for matrixmultiplikation
Vis de resterende to af de ovenstående påstande for matricer ved direkte udregning!
Vi siger at en elementær matrix fremkommer ved at udføre præcis en rækkeoperation på den kvadratiske identitetsmatrix . Hvis denne rækkeoperation er givet ved at multiplicere fra venstre med en matrix , er den tilhørende elementære matrix altså .
Vi indfører betegnelser for de tre typer af elementære matricer.
Lad være den matrix der fremkommer fra identitetsmatricen ved at bytte om på rækkerne med nummer respektive .
Vi lader betegne matricen, som fremkommer ved at gange
-te række i identitetsmatricen af orden med .
Dette er stadig en diagonal matrix, lige som enhedsmatricen, det vil sige at hvis er
.
Til sidst lader vi betegne den
elementære matrix, som fremkommer fra identitetsmatricen af orden ved at
gange -te række med og addere til -te række. Denne
matrix er lig identitetsmatricen med undtagelse af at der i indgangen i -te
række og -te søjle står i stedet for .
Lad
Hvad gælder om ?
er ikke en elementær matrix.
Lad
Hvad gælder om ?
er ikke en elementær matrix.
Lad
Hvad gælder om ?
er ikke en elementær matrix.
Lad
Hvad gælder om ?
er ikke en elementær matrix.
Lad
Hvad gælder om ?
er ikke en elementær matrix.
Lad
Hvad gælder om ?
er ikke en elementær matrix.
Lad
Hvad gælder om ?
er ikke en elementær matrix.
Lad
Hvad gælder om ?
er ikke en elementær matrix.
- At udføre en rækkeoperation på en matrix svarer til at gange den tilsvarende elementære matrix på fra venstre.
- En elementær matrix svarende til en rækkeoperation er invertibel. Dens inverse matrix er den elementære matrix svarende til den inverse rækkeoperation.
Vi begynder med at bevis for (α).
Vi betragter først tilfældet at er en matrix, det vil sige at er en søjlevektor.
For at spare på det dyrbare papir plejer man at skrive en søjlevektor som hvor står for transponering, og gamle vaner er svære at give slip på selv når man skriver for skærmen. Nu regner vi ved at bruge formlen for matrixmultiplikation. Følgende to produkter er nemme at beregne:
Vi er lidt mere forsigtige i det tredie tilfælde.
hvor
Hvis er for , så at
Hvis så er for eller , så at
Det vil sige,
Vi ser at i alle tre tilfælder er multiplikation med en elementær matrix
detsamme som den tilsvarende rækkeoperation, hvis er en søjlevektor.
I det generelle tilfælde kan vi skrive matricen som opbygget af søjlevektorer
af højde , og bruge 4.9
Ifølge specialtilfældet brugt på hver søjle , så fremkommer fra ved at bruge den samme
rækkeoperation på hver søjle i . Men det er det samme som at bruge søjleoperationen på .
Nu ser vi på del (β). Hvis er en elementære matricer der svarer til
inverse søjleoperationer, så er den matrix der fremkommer ved at udføre først søjleoperationen der svarer på identitetsmatricen, og derefter udføre søjleoperationen der svarer til på resultatet. Da disse søjleoperationer er inverse, ender vi med at få identitetsmatricen tilbage, det vil sige at
. Tilsvarende er , så at og er inverse matricer.
En matrix er invertibel hvis og kun hvis dens RREF er . Hvis er invertibel er
RREF for matricen
lig med matricen
En matrix på RREF som ikke er identitetsmatricen bliver
nødt til at indeholde en nulrække. Med andre ord, hvis en matrix
på RREF er invertibel, så er den nødt til at være identitetsmatricen.
Lad os antage at er
invertibel. Som for enhver anden matrix kan vi finde et produkt
af elementære matricer så er RREF for , men da og er invertible bliver denne RREF altså nødt til at være lig
identitetsmatricen.
Modsat hvis matricen har RREF lig identitetsmatricen så findes et
produkt af elementære matricer så og er
invertibel med , da som produkt af elementære matricer er invertibel.
Den sidste påstand følger ved at gange matricen ovenfor på
matricen . Dette matrixprodukt giver . Da
multiplikation med fra venstre giver rækkereduktion, og da
er på RREF, er
den entydigt bestemte RREF af .
Kommentarer/spørgsmål?
Lad være en matrix. Så er invertibel hvis og kun hvis
ligningssystemet
kun har løsningen .
Hvis er invertibel fås
Hvis ikke er invertibel kan vi rækkereducere til en matrix
med en nulrække til sidst (se Sætning 4.33 og Opgave
4.8.12). Men her gælder og
ligningsystemet har en løsning , fordi det har
mindst en fri variabel svarende til at den sidste søjle ikke indeholder
et pivotelement (se afsnit 4.5.1).
4.7 Egenvektorer og egenværdier for en matrix
I eksemplet med stokastiske matricer havde vi brug for at udregne potenser af en matrix . Hvis er en kvadratisk diagonalmatrix er disse operationer meget mere overkommelige.
Hvis
er en kvadratisk diagonalmatrix, så er
Det vil sige en kvadratisk diagonalmatrix opløftes til en potens ved at
opløfte diagonalelementerne til potensen.
Definition 4.1 (af matrixmultiplikation) for to diagonalmatricer
giver
Formlen for er en konsekvens af dette.
4.7.1 Konjugering
For en invertibel matrix findes den inverse matrix og udregningen giver mening for en kvadratisk matrix med samme antal rækker som . Denne operation kaldes konjugering med og matricen kaldes en konjugeret matrix til .
Lad
hvor og .
Lad . Hvad er rigtigt af nedenstående?
hvis .
Lad være en matrix, en invertibel matrix med
søjlevektorer og diagonalmatricen
Så gælder hvis og kun hvis
for .
gælder hvis og kun hvis . Per definition af
matrixmultiplikation følger det at søjlevektorerne i er
for samt at de tilsvarende søjlevektorer i er
.
Lad være en kvadratisk matrix.
Det er ikke oplagt med vores viden nu om en matrix overhovedet har
endeligt mange egenværdier eller hvordan man bærer sig ad med at regne
egenværdier ud. Lad os prøve at kigge på matricer.
- kaldes diagonaliserbar hvis der findes en invertibel matrix så er en diagonalmatrix.
- En vektor kaldes en egenvektor for , hvis og for et tal (som gerne må være 0). Dette tal kaldes for en egenværdi for og siges at være en egenvektor hørende til .
4.7.2 Hvad sker der for små matricer?
At finde egenværdier for en kvadratisk matrix kan omformuleres til at at finde et tal (en egenværdi), så der findes en vektor med . Dette er det samme som at der findes en vektor med Lad os i dette lille afsnit foregribe begivenhedernes gang ved at kigge på en matrix og spørgsmålet: Hvornår findes en vektor så ? Vi ved fra Sætning 4.34 at dette forekommer præcis når ikke er invertibel. Samtidig ved vi fra Sætning 4.33 at er invertibel hvis og kun er rækkeækvivalent med identitetsmatricen. Lad os eksperimentere: Hvis både og er kan ikke være invertibel. Hvis så er og dermed er invertibel hvis og kun hvis Samme betingelse gør sig gældende ved rækkereduktioner ud fra antagelsen . Vi kalder for determinanten for og betegner den . Nu kan vi svare på hvornår har en løsning for en matrix i (4.16). Dette gælder hvis og kun hvis Polynomiet i (4.17) kaldes for det karakteristiske polynomium hørende til . Det vi har vist er altså at en matrix har mindst en egenvektor hørende til egenværdien hvis og kun hvis er en rod i det karakteristiske polynomium. I næste kapitel kommer vi ind på hvad der sker for større matricer ved at definere determinanten af en generel matrix.4.7.3 Differentialligninger som eksempel
Egenværdier og egenvektorer er ekstremt nyttige ved løsning af koblede differentialligninger som hvor . Tilfældet med kun en ubekendt funktion kendes fra radioaktivt henfald. Her støder vi på differentialligningen som har løsningen , hvor er en konstant. Hvis man arbejder ud fra hypotesen om at (4.18) har løsninger af formen så kan man indsætte i (4.18) og komme frem til at hørende til egenværdien . Dette er gennemgået i videoen nedenfor.Kommentarer/spørgsmål?
4.8 Opgaver
4.8.1
Lad være en stokastisk matrix det vil sige alle indgangene i matricen er og samt . Antag at og lad være vektoren Hvorfor er ? Hvordan relaterer det til Eksempel 4.4 om stokastiske matricer?4.8.2
Lad og være invertible matricer. Gør detaljeret rede for at ved brug af den associative lov.4.8.3
Forklar hvorfor matricen ikke er invertibel.4.8.4
For hvilke tal er matricen invertibel.4.8.5
Lad- Find den reducerede række echelon form for .
- Find samtlige løsninger til ligningssystemet