12Singulær værdi dekomposition
Vi så i forrige kapitel hvordan spektralsætningen viser, at enhver hermitesk matrix kan diagonaliseres, ved at lave basisskifte med en ONB bestående af egenvektorer. Nu skal vi se at et næsten tilsvarende resultat holder for alle matricer, også rektangulære matricer. Vi skal nemlig se på kulminationen af kurset: Den meget vigtige Singulær Værdi Dekomposition (SVD). Her laves basisskifte med to (måske forskellige) ONB'er for at opnå en diagonalmatrix. Mere specifikt kommer baserne til at være valgt ud fra de fire fundamentale underrum , , og som vi studerede i slutningen af Kapitel 9.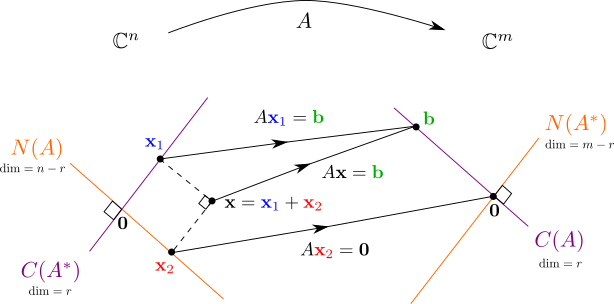
Enhver matrix kan skrives
hvor er en unitær matrix, er en unitær matrix og er en diagonalmatrix.Hvis , så har matricerne følgende struktur:
- har formen hvor de positive tal kaldes de singulære værdier. De store nuller betyder at der udfyldes med indtil er .
- Søjlerne i kaldes de venstre singulære vektorer.
- Søjlerne i kaldes de højre singulære vektorer.
- Der er følgende sammenhæng mellem de første venstre og højre singulære vektorer:
- er en ONB for .
- er en ONB for .
- er en ONB for .
- er en ONB for .
Hvis er en reel matrix, så kan og bestemmes som ortogonal matricer.
12.1 De singulære værdier
Vi tager udgangspunkt i en matrix , og bemærker at hvis vi ganger fra venstre, så får vi en matrix .Denne nye kvadratiske matrix har nogle pæne egenskaber:- er hermitesk og har derfor reelle egenværdier af Sætning 11.3.
- Alle egenværdier for er ikke-negative.
12.2 De højre singulære vektorer
Da er en hermitesk matrix, ved vi fra spektralsætningen (Sætning 11.9) at der findes en unitær matrix , bestående af egenvektorer for , således at Fra (12.2) ved vi at for og for . Samtidig ved vi også at udgør en ONB for hele , hvori og udgør ortogonale komplementer (Sætning 9.34). Samlet set har vi at er en ONB for og er en ONB for .12.3 De venstre singulære vektorer
Vi starter med at definere de første venstre singulære vektorer ud fra de tilsvarende højre singulære vektorer:
Vi skal nu overbevise os selv om, at disse vektorer er ortonormale. Dette gøres ved følgende udregning
og vi husker at er egenvektor for med egenværdi , samt -vektorerne er ortonormale. Vi har derfor
I forrige afsnit så vi at er ONB for , så en afbildning af på denne basis (se f.eks. Figur 12.1) må altså udspænde hele søjlerummet for . Det vil sige, fra (12.4) ved vi nu at er en ONB for .Men hvad så med de resterende venstre singulære vektorer ? De kan udregnes som en vilkårlig ONB for ved brug af f.eks. Gram-Schmidt algoritmen. Bemærk at der er mange forskellige ONB for et vektorrum, så der er en vis valgfrihed her, tilsvarende som der er ved bestemmelse af de sidste højre singulære vektorer, som kan vælges som en vilkårlig ONB for .
12.4 Sammensætning af delresultaterne til SVD
Vi kan nu sætte alle delresultaterne sammen, for at få SVD'en i Sætning 12.2. Da er en ONB for , så er ligheden det samme som for alle . Vi vil altså vise ligheden (12.5).Det første vi bemærker er, at fra ortonormaliteten af -vektorerne gælder altså den 'te standard basis vektor i .Dernæst, ved at gange med diagonalmatricen får vi udtrukket den 'te søjle af : Her er også den 'te standard basis vektor, men denne gang for (da er en matrix).For har vi derfor at , men dette er netop lig med da er vektorer i . Nu mangler vi kun at vise (12.5) for , og her skal vi bruge sammenhængen mellem de venstre og højre singulære vektorer i (12.4):12.5 Eksempel på udregning af SVD
Lad os grundigt gennemgå et eksempel på udregning af SVD for matricen Først skal de singulære værdier og de højre singulære vektorer bestemmes ud fra diagonalisering af den hermiteske matrix Vi får det karakteristiske polynomium som har rødderne og . Dermed er og de singulære værdier for , og vi har Da egenværdier for begge har algebraisk multiplicitet , så vil deres geometriske multipliciteter tilsvarende være af Proposition 8.13. Ved at se på matricerne kan vi forholdsvist let indse at vektorerne udgør ONB'er for egenrummene hørende til henholdsvis og . Dermed er og derfor Nu anvendes (12.4) til at finde de første to venstre singulære vektorer: Til slut skal vi finde som ONB for , hvilket også svarer til nulrummet for matricen da . Ved at inspicere og , ser vi at er en enhedsvektor ortogonal med og . Derfor er og vi har .12.6 Approksimation med lav-rang matricer
En mere kompakt måde at opskrive en SVD på, som tager højde for at de sidste -vektorer og -vektorer ikke har betydning for matrixproduktet, er ved kun at se på de første søjler i og ; disse forkortede matricer kaldes og . Tilsvarende kalder vi for diagonalmatricen med de singulære værdier i diagonalen. Vi har nu helt tilsvarende at Den sidste lighed i (12.6) kommer af at er en diagonalmatrix, og det viser hvordan en rang- matrix altid kan skrives som en sum af rang- matricer.
En fordel ved den kompakte SVD er, at matricerne og kan være betydeligt mindre end for den ''fulde'' SVD. Dog skal man passe lidt på, da og generelt ikke er kvadratiske matricer, og er derfor ikke unitære. Deres søjler er dog stadig ortonormale, så der gælder derfor
men i den omvendte rækkefølge og vil disse ikke være identitetsmatricer, medmindre at matricerne er kvadratiske (dvs. hvis eller ).
Dette princip bliver blandt andet brugt til at udvælge det mest relevante data inden for statistik og går også under navnet Principal Component Analysis (PCA). Dog har man ofte at gøre med symmetriske matricer i PCA, så her kan man også bruge spektralsætningen til at lave en egenværdidekomposition.
En anvendelse som er let at visualisere er til komprimering af billeder, hvor man ofte ikke ønsker at gemme hver eneste pixel i et stort billede, men i stedet vil anvende nogle ganske få komponenter af en SVD til at lave en lav-rang approksimation. I et gråtone billede svarer farven i en pixel til et tal i en stor matrix (for farvebilleder: tre matricer). Overvej følgende billede, hvor matricen har en rang på .
Originalt billede med matrix af rang Herefter approksimeres matricen for billedet ud fra (12.8) med forskellige værdier af .
Approksimation med 
Approksimation med 
Approksimation med Ud fra kun lidt over procent af de singulære værdier kan man allerede sagtens se hvad billede forestiller, dog med en lidt synlig grynet struktur som svarer til komprimeringen af billedet.
For at forstå hvorfor dette er en fornuftig måde at approksimere på med matricer af lav rang, skal vi kigge på hvilken fejl der bliver begået i approksimationen, altså hvad er forskellen . Ved at se på (12.6) og (12.8) har vi:
Fejlen kommer altså fra leddene med de mindste singulære værdier. Men for at kunne give et konkret tal der beskriver den procentvise fejl, så skal vi først introducere en måde at beskrive størrelsen af en matrix; en matrixnorm.12.6.1 Matrixnormer
En matrixnorm skal opfylde tilsvarende krav som andre vektornormer; forklaringen for dette er at man udstyrer et vektorrum bestående af de komplekse matricer med en norm, altså er vektorerne i disse vektorrum matricer.Nogle af de mest almindelige matrixnormer kan opskrives ved brug af matricens singulære værdier:
Disse normer har nogle særlige navne. kaldes den spektrale norm, matrix -normen eller Schatten -normen, kaldes enten spornormen, nuklearnormen eller Schatten -normen, og til sidst har vi som kaldes enten Frobeniusnormen, Hilbert-Schmidt normen eller Schatten -normen.
- Der er flere matrixnormer som kan defineres ud fra singulære værdier, eksempelvis for ethvert kan defineres Schatten -normen: Her har vi dog været forsigtige med notationen, da der også er andre -normer der normalt skrives , men som generelt ikke kan opskrives fra de singulære værdier (bortset fra den spektrale norm).
- Et resultat som ikke bliver gennemgået i disse noter er, at alle normer på et endelig dimensionelt vektorrum er ækvivalente. Det betyder at hvis man har to normer og , så findes der nogle positive konstanter og så der gælder for alle . Derfor er forskellen på de enkelte normer ofte ikke så vigtig som man skulle tro. Dog kan nogle anvendelser have brug for specifikke egenskaber af en norm, f.eks. om normen er relateret til et indre produkt, hvilket ofte bruges til at simplificere optimeringsalgoritmer.
For enhver matrix , gælder følgende formler:
Vi bruger matricens SVD , og vi kommer til at udnytte at unitære matricer bevarer den Euklidiske norm:
Tilsvarende gælder at for alle .Nu viser vi formlen for den spektrale norm,
Her brugte vi både at vi kunne fjerne i tælleren da den bevarer normen, og tilsvarende at vi kunne introducere i nævneren.Nu skal vi bruge at er en invertibel matrix, hvilket betyder at for en vektor gælder at hvis og kun hvis for et . Mere specifikt kan vi erstatte maksimum over med et maksimum over og indsætte i (12.11):
Ved at udnytte at er den største af de singulære værdier har vi derfor
Vi kan nu kombinere (12.12) og (12.13) for at få slutresultatet
hvilket viser at .Nu skal vi vise formlen for Frobeniusnormen, og hertil bruger vi notationen at betegner den 'te række i matricen . Vi har derfor at
Vi skal nu udnytte at er den 'te søjle i og derfor ligger i , samt at netop er en ONB for . I Proposition 9.11 så vi netop hvordan man bruger en ONB til at finde normen af en vektor:
Da er den 'te række i , så har vi derfor at det indre produkt lige præcis er det 'te element af matrix-vektor produktet . Samtidig ved vi også at fra Sætning 12.2, hvilket giver
hvor vi til sidst brugte at -vektorerne er enhedsvektorer. Samlet set giver (12.14) og (12.15) at .
Der gælder følgende resultater for normerne i (12.10), hvor er en matrix med rang :
- ,
- ,
- .
Vi gør brug af (12.10) til at vise (i), (ii) og (iii).(i): Da de singulære værdier er positive, og er den største, har vi:
(ii): Tilsvarende vurderinger, hvor det anvendes at kvadratrodfunktionen er en voksende funktion, giver:
(iii): Vi anvender nu at de singulære værdier er positive, til at vise første ulighed:
Til den anden ulighed bruger vi Cauchy-Schwarz ulighed (Sætning 9.5) på vektorerne og i :
Til at bevise (12.16) for de tre matrixnormer, er det nok at vise det for den spektrale norm, da den er den mindste af (i) og (ii). Det er klart at uligheden gælder hvis , fordi så er begge sider lig 0. Antag nu at . Her bruger vi formlen fra Proposition 12.7:
Det oplyses at følgende rang-3 matrix har de nedenfor angivne SVD og kompakt SVD:
Vi kan nu bestemme approksimationerne og ved
Disse lav-rang approksimationer til har via (12.18) følgende relative fejl:
og
Hvis vi holder os til den spektrale norm, så svarer det til at har en relativ fejl på 75 procent, mens har en relativ fejl på 25 procent.
12.7 Numerisk teori og anvendelser
12.7.1 Pseudoinvers og mindste kvadraters løsning
I løbet af kurset har vi gang på gang stødt på singulære matricer, om det så er kvadratiske matricer der ikke er invertible eller om det er rektangulære matricer. På den anden side, ved vi at det altid er muligt at finde (mindst én) mindste kvadraters løsning til et ligningssystem.Nu skal vi se hvordan vi ud fra en matrix kan bruge dens SVD til at opskrive en såkaldt Moore-Penrose pseudoinvers .
Lad være SVD af en matrix. Vi definerer nu en (bemærk: omvendte dimensioner) diagonalmatrix
Følgende matrix kaldes (Moore-Penrose) pseudoinvers af :
Vektoren
er en mindste kvadraters løsning til ligningssystemet .
Beviset er en direkte udregning, hvor vi indsætter kompakt SVD udtryk for , og , samt gør brug af (12.7):
Vi har altså at er en løsning til .
Her indser vi at er en linearkombination af de første af -vektorerne, som vi fra Sætning 12.2 ved er en ONB til . Det vil altså sige, at er ortogonal på enhver vektor , og derfor giver Pythagoras sætning at
for alle , og der er kun lighed til sidst hvis . Vi har vist følgende resultat.
Til et lineært ligningssystem eksisterer en entydig mindste kvadraters løsning som har minimal norm, og den kan findes med formlen i Sætning 12.11.
Vi fortsætter fra Eksempel 12.9, og finder den pseudoinverse til
hvilket fra Definition 12.10 er
Hvis vi overvejer ligningssystemet med , så vil den entydige mindste kvadraters løsning med minimal norm være givet ved
12.7.2 Konditionstal og numerisk stabilitet
Vi starter nu med at fokusere på et ligningssystem hvor er en generel matrix. Her kan man tænke på som en matematisk model for et system i f.eks. fysik eller kemi, og betegner måledata. I en praktisk situation vil der typisk være små målefejl og tilsvarende vil en computerudregning have afrundingsfejl, så i virkeligheden løser man måske et andet problem hvor vektoren betegner en ukendt målefejl.Spørgsmålet er nu, hvor stor påvirkning kan en sådan målefejl have på vores slutresultat i forhold til resultatet uden målefejl? Altså hvor stor er den relative fejl: i forhold til den relative målefejl:
Lad være en matrix med rang . Overvej mindste kvadraters løsningerne og . Så gælder
Her er antaget at og .
Eksempelvis vil en matrix med konditionstal på kunne forøge en lille relativ målefejl på til en ganske stor relativ fejl på (mindste kvadraters) løsningen, svarende til . I mange praktiske sammenhænge, og især med meget store matricer, er det ikke ualmindeligt at man ser så store konditionstal, og i særligt ustabile problemer vil det være meget større. Men som man kan se nedenfor, kan dette også forekomme for helt små matricer.
Lad os overveje et ligningssystem med matricen
for et tal . Matricen har konditionstal på , så hvis f.eks. fås et meget stort konditionstal på . I en praktisk situation kunne være et resultat af nogle numeriske beregninger, hvor der på grund af afrundingsfejl står i stedet for 0.Lad nu og hvor svarer til en lille fejl på andet koordinat. Løsningen til systemerne og opfylder
Det ses tydeligt at selv for en lille målefejl kan blive stort hvis er meget mindre end . Hvis man sætter sker der noget besynderligt: Matricen får det mere overskuelige konditionstal på , altså systemet er pludselig blevet numerisk stabilt. Nu er matricen ikke længere invertibel, så i stedet skal den pseudoinverse bestemmes, hvilket er
I lige dette tilfælde vil fejl på andetkoordinatet af -vektoren slet ikke have nogen påvirkning af mindste kvadraters løsningen med minimal norm. Specifikt kan man ikke vælge nogen vektor så den relative fejl bliver større end .
12.7.3 Trunkeret SVD og Tikhonov regularisering
Ud fra konditionstallet er det i anvendelser typisk ikke størrelsen af der bliver problematisk. Derimod er det ofte at nogle af de singulære værdier, og derfor blandt andet , kommer meget tæt på nul. Et stort konditionstal er konsekvensen, hvilket gør løsning af numerisk ustabilt (se Sætning 12.14) i forhold til små ''tilfældige'' fejl eksempelvis fra målinger i anvendelser, numeriske approksimationer eller afrundingsfejl i computerberegninger.I dette afsnit skal vi undersøge hvordan man ofte i praksis tilnærmelsesvist løser numerisk ustabile lineære ligningssystemer.Den første tilgang er den simpleste: Vi erstatter med en lav-rang approksimation hvor typisk er meget mindre end rangen af . Vi har netop at svarende til at vi har fjernet bidrag fra de mindste singulære værdier af . Vi kalder nu
for en trunkeret SVD (TSVD) regularisering af . Hvis vi kigger nærmere på (12.21) svarer TSVD til at fjerne bidrag med store værdier af , som ganges på der kan være ''forstyrret'' af tilfældig støj:
Antal led i beregningen af TSVD kaldes også en regulariseringsparameter, og valget af er en afvægtning af to faktorer:
- Desto mindre er, desto dårligere approksimation er til , hvilket afspejler sig i som approksimativ løsning til .
- Tilgengæld er stabiliteten for beregningen af bedre desto mindre er.
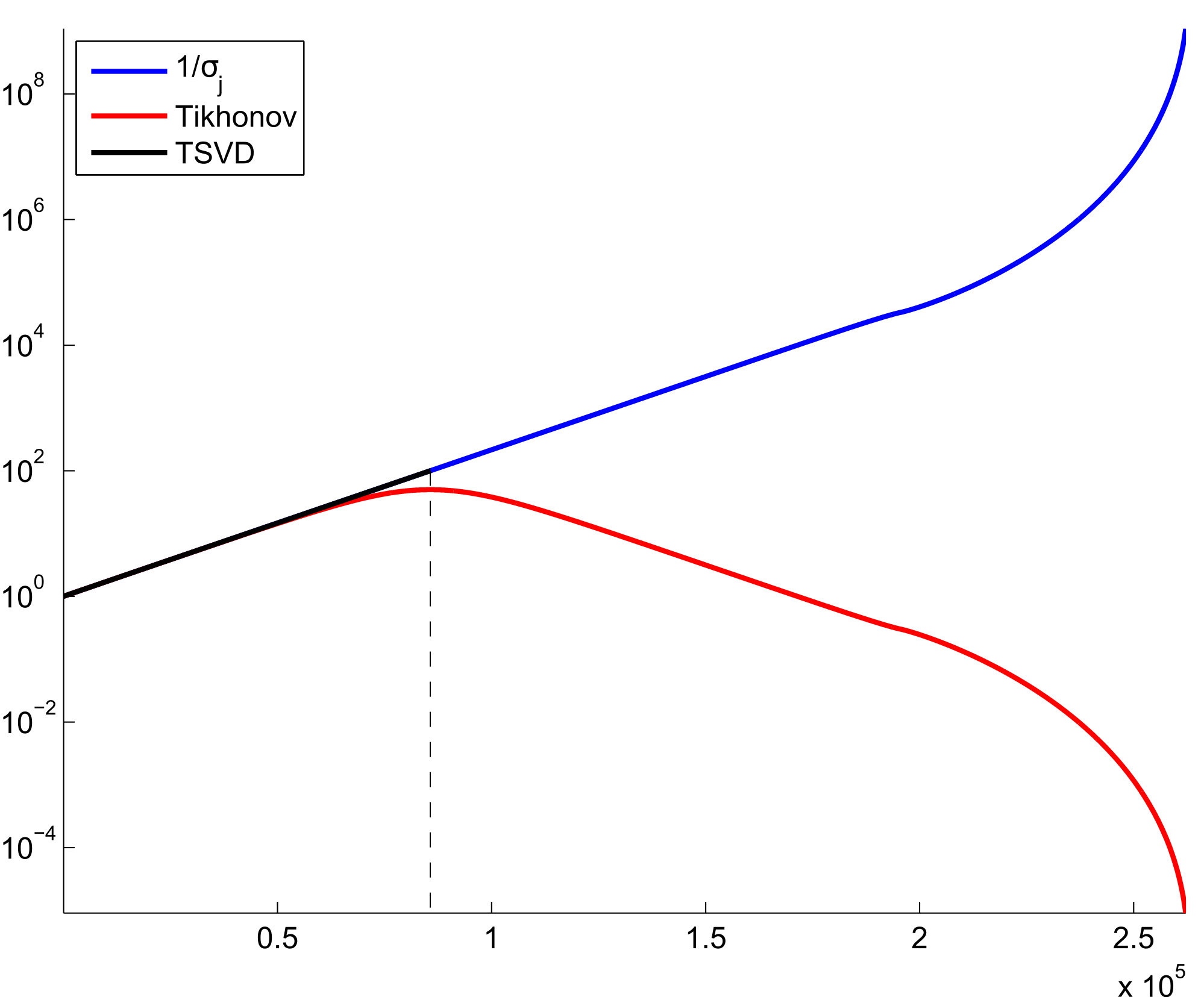
Dette kaldes en Tikhonov regularisering af . Metoden er navngivet efter russisk matematiker Andrey Nikolayevich Tikhonov som har været en meget markant indflydelse på moderne metoder i numerisk analyse.Rollen af i Tikhonov regularisering svarer til den reciprokke rolle af i TSVD. For lille fås lille approksimationsfejl men stor beregningsfejl, og omvendt for stort .En traditionel måde at karakterisere Tikhonov regularisering på, er som et minimeringsproblem der generaliserer mindste kvadraters metoden ( er mindste kvadraters metode):
For er den entydige løsning til minimeringsproblemet
Vi starter med at indse at
hvor
Dermed er minimering af (12.28) svarende til mindste kvadraters løsning for (Sætning 10.6). Derudover, da , gør identitetsmatricen i at samtlige søjler for RREF af er pivotsøjler, så . Af Sætning 10.4 er der en entydig mindste kvadraters løsning til .Vi bestemmer nu komponenterne til normalligningerne. Vi begynder med :
Ved at udvide til en diagonalmatrix, hvor er i øverste venstre hjørne, samt anvende at har vi samlet set
Dens inverse bliver dermed
Tilsvarende har vi
Vi kan nu skrive mindste kvadraters løsningen til som
I udregningen af produktet blev anvendt strukturen af kendt fra Sætning 12.2.
Det er værd at bemærke at for har minimeringsproblemet i Sætning 12.17 en entydig løsning. For har det tilsvarende minimeringsproblem ikke nødvendigvis en entydig løsning (mængden af løsninger afhænger af ), fordi dette svarer nemlig til mindste kvadraters problemet (Sætning 10.6). Her skal bemærkes at når , og så er som sagt den entydige mindste kvadraters løsning som har minimal norm (Proposition 12.12). Hvis man lader i løsningen af minimeringsproblemet i Sætning 12.17, er det netop denne mindste kvadraters løsning som konvergerer mod.

12.8 Opgaver
Ud fra en SVD af matrix , hvad er SVD af ?
Ud fra en SVD af matrix , hvad er egenværdierne af ? Hvad er nogle tilhørende egenvektorer?Hint
Brug resultatet fra Opgave 12.20, og indsæt SVD for og i produktet.
Det oplyses at for enhver unitær matrix . På baggrund af dette, vis at for enhver kvadratisk matrix med fuld rang, er lig produktet af de singulære værdier for .
Find de singulære værdier for matricen
Summen af de singulære værdier skal give .
Det oplyses at den reelle matrix
har en SVD med matricerne
- Udregn lav-rang approksimationerne (rang 1) og (rang 2) til . (Husk den transponerede af i SVD'en).
- Udregn de relative fejl og i din favorit matrixnorm.
Find kompakt SVD for matricen
I forlængelse af Opgave 12.25, find den entydige mindste kvadraters løsning med minimal norm for ligningssystemet