Vi skal nu bruge det generelle -test i multinomialmodellen
til at teste, at indsamlede data følger en
bestemt fordeling. Dette går under navnet Goodness of fit test.Ideen er, at talaksen deles op i en række intervaller,
lad os sige intervaller,
hvorefter der tælles op, hvor mange af observationerne
der ligger i de forskellige intervaller
(her bruger vi og , og intervallet
går fra til med ,men ikke , indeholdt i intervallet).
Dette svarer til, at de observationer er fordelt på kasser,
og de tilhørende stokastiske variable for antallene er
derfor multinomialfordelt,
På grund af den måde data er indsamlet på, kan vi skrive
I modellen er disse sandsynligheder vilkårlige:
Vi ønsker at teste, at har en bestemt fordeling, der eventuelt
afhænger af en parameter der kan variere i området
For at formulere dette betegnes fordelingsfunktionen
(sandsynligheden for at ligge til
venstre for et punkt) med Vi kan nu formulere
en ny model, eller specificere en hypotese, ved
Her skal erstattes af 0, og
skal erstattes af 1.
Situationen her svarer til det generelle -test med hypotesen
se
ligning (1.3.2).
Når skøn over er fundet, bliver de
forventede antal
For at bruge Resultat 1.3.1
skal man have, at alle de forventede er større end eller lig med 5.
Hvis dette ikke er opfyldt, gør man traditionelt det, at man slår
kasser sammen for at få kravet opfyldt.Typisk vil man, når man laver et goodness of fit test, lave en grafisk
fremstilling af data i form af et histogram, og i dette histogram indtegne
tætheden for den fordeling, der undersøges.
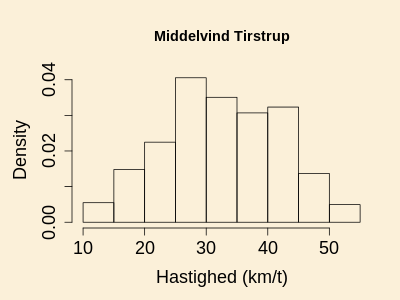
1.4.1 Opgave med besvarelse: vindhastigheder
Data i denne opgave består af den daglige middelvind i Tirstrup gennem
hele 2019. Data er hentet hos
Iowa Environmental Mesonet,
og de daglige middelvinde er givet i kilometer per time.
Et tæthedshistogram er vist i nedenstående figur, og data er
indskrevet i kodevinduet nedenfor.
Data af denne type beskrives ofte med
weibullfordelingen,
og i opgaven her skal der laves et goodness of fit test for,
om weibullfordelingen beskriver data. Hvis den stokastiske variabel
er weibullfordelt, gælder der
hvor kaldes en formparameter og en skalaparameter.
Tæthedsfunktionen og fordelingsfunktionen for en weibullfordeling
beregnes i R med kommandoerne
dweibull(x,,) og
pweibull(x,,).
Til at lave goodness of fit testet skal der benyttes en
intervalinddeling med intervaller af længde 3 startende i nul.
Desuden skal der bruges, at maksimum likelihood skønnene baseret på
antallene i de forskellige intervaller er
og Idet den største værdi i data er 54, laver vi intervalinddelingen
Antallene i de
forskellige intervaller betegnes
og findes i R med kommandoen
hist(vind,breaks=c(0:18)*3)counts.
For de tilhørende
stokastiske variable vælges modellen
Vi ønsker at teste hypotesen
hvor er fordelingsfunktionen for en weibullfordeling.
Fra opgaveformuleringen vides, at skønnene over de ukendte parametre er
og De forventede
kan derfor beregnes som
Fra R-beregningen får vi de observerede (første række)
og forventede
(anden række):
For at få alle de forventede større end eller lig med 5 slås de
fire første kasser sammen. Dette giver det observerede antal 1 og
det forventede antal 5.02. Efter denne sammenlægning er der
15 kasser, hvorfor antallet af frihedsgrader i -fordelingen bliver
15-1-2=12, idet vi under hypotesen har to frie parametre ( og ).
-teststørrelsen for vores hypotese beregnes fra formlen
hvor
og er de observerede og forventede, efter at kasser er slået
sammen. Beregningen i R viser, at og den
tilhørende -værdi er
Da -værdien ligger langt over 0.05, strider data ikke mod
hypotesen om, at de daglige middelvinde er weibullfordelt.I R-kørslen nedenfor har jeg også indtegnet weibulltætheden i
histogrammet. Desuden binder jeg de forskellige dele af output sammen ved
at bruge R-kommandoen list.
I R-kørslen nedenfor har jeg også indtegnet weibulltætheden i
histogrammet. Desuden binder jeg de forskellige dele af output sammen ved
at bruge R-kommandoen list.
For at illustrere -approksimationen til fordelingen af
simuleres i kodevinduet nedenfor poissonfordelte data, og
der laves et goodness of fit test for, at data er poissonfordelt.
I den kode der vises, simuleres observationer fra en
poissonfordeling med parameter . For goodness of fit testet
deles op i 5 kasser svarende til de mulige værdier
og værdier større end eller lig med 4. Valget af de 5
kasser sikrer, at der er meget lille sandsynlighed for at få et
forventet antal mindre end eller lig med 5.
Kør koden. Erstat "c()" med kode for at beregne et 95%-konfidensinterval
for sandsynligheden for, at er større end
95%-fraktilen i en -fordeling.