Jeg har lavet en funktion forward, der laver beregninger til et
enkelt trin i forward selektion. Koden til funktionen ligger i filen
Rfunktioner.txt og er kopieret ind i kodevinduet
nedenfor. Input til funktionen er en
matrice med værdierne
af de forklarende variable for prøver,
en vektor med responsværdierne og en vektor
med numrene på de variable, der allerede er inkluderet i modellen.
Hvis matricen hedder og responsvektoren starter man med kaldet
forward(T,x).
Fra output aflæses hvilken variabel, man vil
starte med at inkludere i modellen, og næste kald til funktionen bliver
forward(T,x,c()), hvor er nummeret på den variabel,
der inkluderes.
Efter at variablen er inkluderet i modellen, findes
det næste led ved kaldet forward(T,x,c()),
dernæst forward(T,x,c()), og så videre.
Output fra et kald til forward er spredningsskønnet
fra den multiple regressionsmodel med et nyt led inkluderet
(altså et led mere end i kaldet til forward), en vektor med
numrene på de variable der indgår i modellen, og en vektor med
-værdierne for test af at en regressionskoefficient er nul. Det er
den sidste indgang i vektoren med -værdier, der bruges til at
vurdere, om man vil inkludere det sidst fundne led, og dermed om man vil
fortsætte forward selektionsproceduren.I kodevinduet nedenfor hentes datasættet fra afsnit
5.5, men i stedet for kun at bruge de første
40 målinger bruges her alle 50 målinger.
Det essentielle trin i beregningen er "for"-løkken inde i
forward-funktionen. Her prøver man for alle de
forklarende variable, der endnu ikke er med i modellen, at tilføje
en af disse og beregne spredningskønnet når
variablen er tilføjet. I den efterfølgende kommando which.min(res)
finder man nummeret på den variabel, der giver den mindste værdi
af Estimation af den multiple regressionsmodel foregår
ikke her med lm, som I ellers er vant til, men med
funktionen lsfit. I den sidste er input ikke en modelformel,
men derimod en matrice med værdierne af de forklarende variable.
Efter at den nye variabel er fundet, estimeres den
multiple regressionsmodel, og -værdier beregnes ud fra
standard errors og opslag i en -fordeling.
Kør koden, og se, at den første variabel, der medtages, er nummer 151, og at
den tilhørende -værdi er Kør nu koden igen, hvor
forward(spek,brix) udskiftes med
forward(spek,brix,c(151)). Her vil du
se, at variablen nummer 221 inkluderes, og den tilhørende -værdi er
Fortsæt selv forward selektionsalgoritmen, og overvej,
hvornår du vil stoppe. Jeg har også lavet en funktion cvForward til
at lave crossvalidation (leave one out) beregningerne for
en forward selektionsmodel med et givet antal variable.
Input til funktionen er matricen med værdierne
af de forklarende variable, vektoren med responsværdierne og et tal,
der angiver, hvor mange led der skal
medtages i forward selektionsmodellen.
I kodevinduet nedenfor kaldes funktionen med 3 som antal led i
forward selektionsmodellen.
Output fra cvForward er en vektor med prædiktionsspredningen
beregnet ved leave one out crossvalidation, når der medtages henholdsvis
1 variabel i forward selektion, 2 variable og 3 variable, hvor 3 var
angivet i kaldet til funktionen. Det tager cirka et minut at køre
koden nedenfor.
I funktionen cvForward indeholder matricen mat alle
de kvadrerede prædiktionsfejl, rækker svarer til observationsnummer
og søjle angiver, hvor mange led der tages med i forward selektion.
"For-løkken" over er selve crossvalidation skridtet, hvor den
'te observation tages ud, og træningssættet består af de
resterende observationer. For hvert træningssæt genemføres
forward selektion, og hver gang en ny variabel er tilføjet,
beregnes den prædikterede værdi for den observation, der er udeladt
af træningssættet.
Kør koden (det tager nogle minutter),
og vurder ud fra output, hvor mange led du vil medtage i
din model.
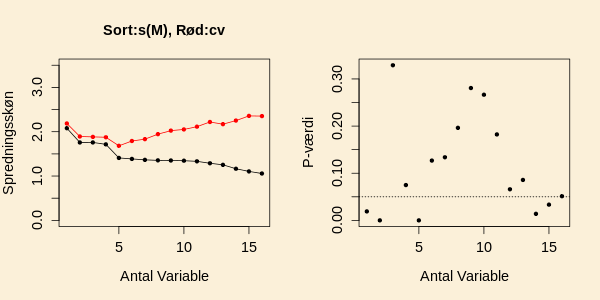
Resultaterne ved at køre forward 15 gange er vist i figuren nedenfor.
Ud fra figuren med -værdier vil man nok vælge forward selektionsmodellen
med 5 variable, hvilket stemmer overens med den røde kurve
med prædiktionsspredningen fra leave one out crossvalidation.
Formelt vil man ved forward selektion med en grænseværdi på 0.05
kun medtage 2 variable, men crossvalidation viser, at det
er bedre med 5 variable.
Den følgende tabel viser de fem første variable, der kommer med
ved forward selektion, baseret på henholdsvis de
40 første målinger, som i afsnit 5.5,
og baseret på alle 50 målinger som i dette afsnit.
Skønnet over spredningen fra den multiple regressionsmodel med
de 5 variable fra en forward selektion er hvorimod
prædiktionsspredningen er Brixværdien
ligger i disse data spredt ud mellem 11 og 20. Med en
spredning på omring 1.5 er der, set relativt til variationsområdet,
en stor usikkerhed i bestemmelsen af brixværdien.
Forward selektion tager variable med i rækkefølgen
, , , og SV, hvorefter -værdi bliver over 0.05.
Crossvalidation giver mindst prædiktionsspredning med
4 variable.