Afsnit 1.10: Opgaver til kapitel 1
Opgave 1.1: Goodness of fit test: Uniform fordeling
I 2009 publicerede Pieter Vermeesch en lille note med den provokerende
titel
Lies, damned lies, and statistics (in geology).
I noten betragter forfatteren
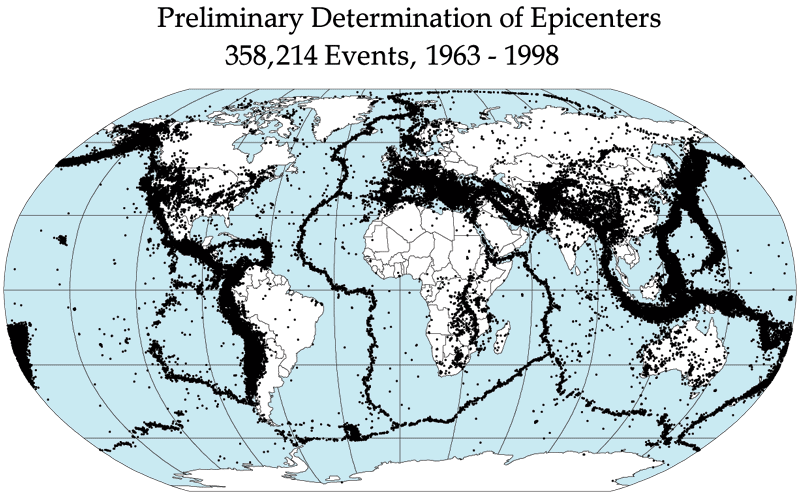
118415 jordskælv af styrke 4 eller over på Richterskalaen
i perioden 1/1-1999 til 1/1-2009 (data fra
earthquake.usgs.cov) og
fordeler disse på ugedag. Billedet her viser, hvor jordskælv optræder.
 Data kan ses i den følgende tabel
og findes i filen JordskaelvDag.csv.
Data kan ses i den følgende tabel
og findes i filen JordskaelvDag.csv.
- Opstil multinomialmodellen for disse data, hvor sandsynlighederne for at falde i de syv kasser er vilkårlige.
- Opskriv, inden for den opstillede multinomialmodel, hypotesen om ligelig fordeling på de syv ugedage. Udregn de forventede antal, og lav -testet for hypotesen. Hvad bliver konklusionen af testet ?
- Lav et -test for en ligelig fordeling, både for alle jordskælv med en styrke over 5 og for delmængden, hvor efterskælv er fjernet.
Opgave 1.2: Goodness of fit, poissonfordeling
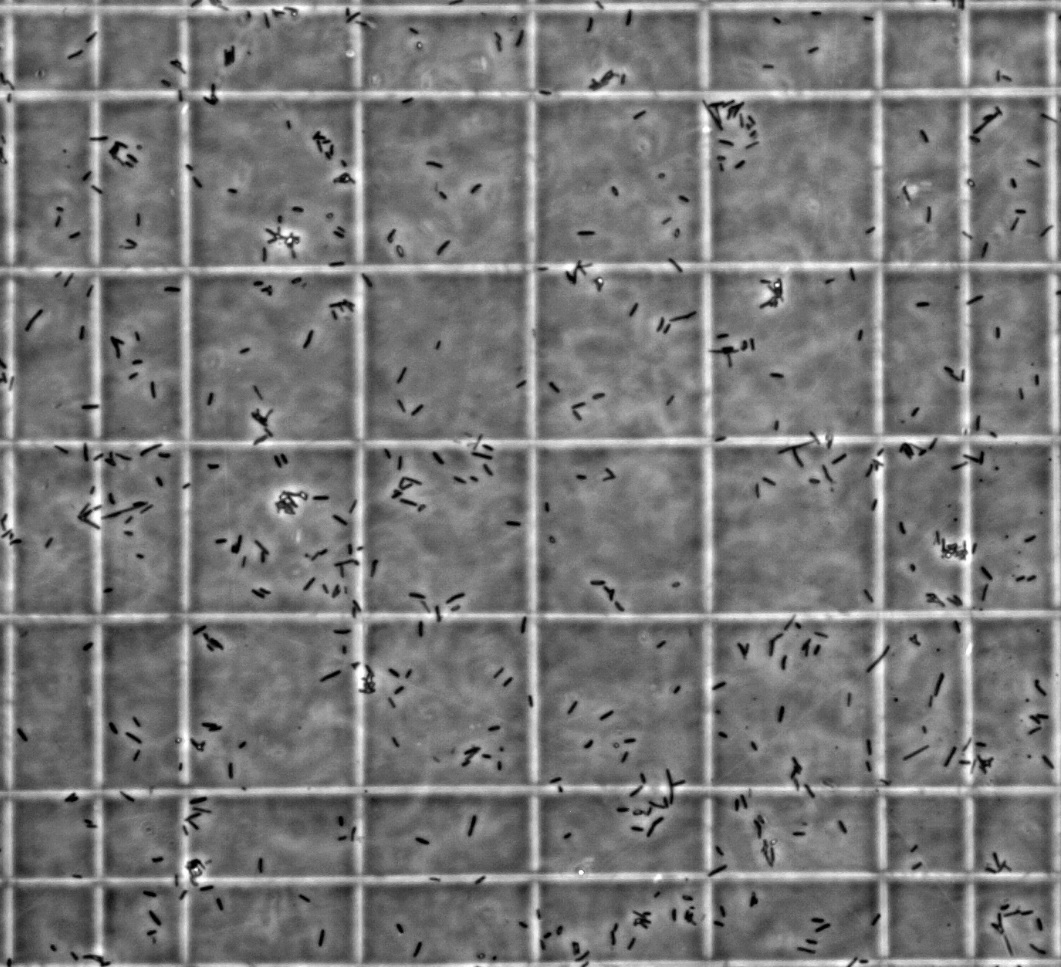
Data i denne opgave tager udgangspunkt i forsøg med
bakterieceller, hvor man ofte har behov
for at tælle, hvor mange af
disse man har i en given opløsning. Dette gøres ved at udtage en
mindre del af opløsningen og tage billede af denne i et mikroskop, hvor
bakterierne så kan tælles. Et eksempel på et sådant billede er vist
nedenfor, hvor de små sorte områder er
enkelte
E. coli
bakterier. De store områder i midten af billedet er
hver på og her inden for tælles antallet
af bakterier.
For at sikre konsistens
tælles en bakteriecelle, der ligger ind over en kant, kun med hvis det er
den venstre eller den øverste kant, der berøres.
 I filen CelleData.txt ligger
data fra optælling fra
14 sådanne billeder, hver med 16 områder. Data er indsamlet
med henblik på opgaven her og stillet til rådighed af
Morten Bormann Nielsen.
I filen CelleData.txt ligger
data fra optælling fra
14 sådanne billeder, hver med 16 områder. Data er indsamlet
med henblik på opgaven her og stillet til rådighed af
Morten Bormann Nielsen.
- Indlæs de 224 kvadrattællinger med ordren nColi=scan("CelleData.txt"). Lav et antalshistogram af data med intervalendepunkter endePkt=c(4:32)-0.5 (det første interval er fra 3.5 til 4.5, svarende til at den mindste værdi i nColi er 4, og det sidste interval er fra 30.5 til 31.5, svarende til at den største værdi i nColi er 31). Indsæt titler på akserne i figuren ved at benytte xlab og ylab i kaldet til hist. Placer antallet af observationer i hvert interval i en vektor antal. Vælg et af intervallerne ud, og eftervis antallet i antal ved en direkte optælling blandt de 224 dataværdier.
- Opskriv multinomialmodellen for den stokastiske antalsvektor Antal, hvor sandsynligheden for at falde i de forskellige kasser er vilkårlig.
- Opskriv, inden for din multinomialmodel, hypotesen om, at antallet af bakterier i et kvadrat er poissonfordelt. Beregn de forventede antal under hypotesen. Hertil kan du benytte koden nedenfor. I R beregnes punktsandsynligheder i poissonfordelingen med dpois(x,lambda), og sandsynligheden for en værdi mindre end eller lig med beregnes med ppois(x,lambda). Forklar, at koden giver de forventede værdier.Indtegn de forventede antal i histogrammet fra spørgsmål (a) som en rød kurve med kommandoen lines(c(4:31),forvent,col=2), hvor forvent er vektoren med de forventede antal.
- Lav -testet for hypotesen, at antal bakterier i et kvadrat er poissonfordelt. Slå kasser sammen, hvis de forventede ikke er større end 5 (slå kasser sammen fra hver sin ende, indtil det forventede antal er større end 5).Hvad bliver konklusionen af dit goodness of fit test ? Kan du give en forklaring på resultatet ?
Konklusionen af ovenstående analyse er, at poissonfordelingen ikke er
en særlig god beskrivelse af data. Man kan indse, at de 224 tællingerne
viser større spredning, end hvad man forventer i en poissonfordeling.
Fortolkningen af dette er, at bakterierne ikke er tilfældigt spredt ud
over området, nogle områder har større intensitet af bakterier end
andre områder (bakterierne klumper).
Opgave 1.3: Goodness of fit, normalfordeling
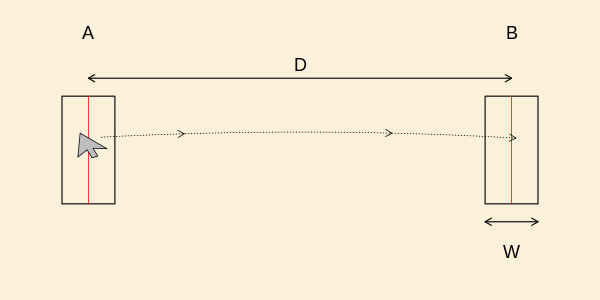
I menneske-maskine-interaktion betragtes
blandt andet, hvordan man flytter pointeren på en computerskærm via musen.
Figuren nedenfor viser en typisk opstilling, hvor en person
skal flytte pointeren fra område til område
 Data er
simulerede baseret på informationen i figur 1 i artiklen
An error model for pointing based on Fitts' Law.
Der er 269 observationer målt relativt til
midtpunkt af målområdet (enheden angives i figuren som "pixels").
Data ligger i filen Position.txt.
Opgaven går ud på at lave et goodness of fit test for,
at pointerpositionen kan beskrives med en normalfordeling.
Data er
simulerede baseret på informationen i figur 1 i artiklen
An error model for pointing based on Fitts' Law.
Der er 269 observationer målt relativt til
midtpunkt af målområdet (enheden angives i figuren som "pixels").
Data ligger i filen Position.txt.
Opgaven går ud på at lave et goodness of fit test for,
at pointerpositionen kan beskrives med en normalfordeling.
- Indlæs de 269 positioner med kommandoen
scan("Position.txt"), og placer
disse i variablen pointer.
Lav et tæthedshistogram af data med intervalinddelingen
endePkt=c((-9):8)*2+0.5.
Placer antallet af observationer i hvert
af de 17 intervaller i en vektor antal.Hvis positionen af pointer
skal beskrives med en normalfordeling, er det bedste valg
af middelværdi og det bedste valg af spredning er
Indtegn normalfordelingstætheden i histogrammet med
kommandoen
curve(dnorm(x,0.1843,4.9938),from=-20,to=20,add=TRUE)
- Opskriv multinomialmodellen for den stokastike vektor Antal, hvor sandsynlighederne for at falde i de forskellige intervaller er vilkårlige. Opskriv dernæst hypotesen, at sandsynlighederne for at falde i de 17 intervaller er givet ved sandsynlighederne for intervallerne i en normalfordeling med middelværdi og spredning Husk at i denne sammenhæng skal det første interval opfattes som intervallet fra minus uendelig til -15.5, og det sidste interval skal opfattes som intervallet fra 14.5 til uendelig. Beregn de forventede antal under hypotesen. Hertil kan du benytte koden nedenfor. I R beregnes sandsynligheden for en værdi mindre end eller lig med i en normalfordeling med kommandoen pnorm(x,,). Forklar, at koden giver de forventede værdier.
- Lav -testet for hypotesen, at pointerpositionenen er normalfordelt. Kan disse data beskrives med en normalfordeling ?
I bogen
Human-Computer Interaction: An Empirical Research Perspective
omtales kort et
eksperiment, hvor kvinder og mænd observeres
for at vurdere deres måde at scrolle i en
tekst.
Hver person klassificeres efter, om vedkommende bruger enten rullehjulet
på musen til at scrolle i en tekst, bruger rullepanel på
skærmen eller bruger tastaturtasterne.
Der er 65 kvinder og 43 mænd i undersøgelsen.
Fordelingen på de tre metoder for henholdsvis
kvinder og mænd
kan ses i tabellen nedenfor.
Vi ønsker med data at se, om
der er kønsspecifikke måder at arbejde med computeren på.
- Opstil den statistiske model, hvor tælletallene for hvert køn følger sin egen multinomialfordeling. Angiv inden for den opstillede model hypotesen, at der er samme sandsynlighedsvektor for kategorierne (Rullehjul, Rullepanel, Tastatur) for de to køn.
- Undersøg, om data er i overensstemmelse med hypotesen om samme sandsynlighedsvektor for kategorierne (Rullehjul, Rullepanel, Tastatur) for de to køn (benyt eventuelt R-koden fra det skjulte kodevindue i eksempel 1.6.2).
Opgave 1.5: Poissonmodel med proportionale parametre
Antallet af jordskælv i et bestemt område og med en styrke i et givet
interval beskrives ofte med en poissonfordeling. Et eksempel er
artiklen
A Poisson model for earthquake frequency uncertainties in seismic hazard analysis.
I artiklen
betragtes blandt andet jordskælv i New Zealand.
Information om disse kan findes på nettet under adressen
info.geonet.org.nz. Data i
tabellen nedenfor viser
antallet for tre styrkeintervaller og for perioden 1930-2015.
Styrken er på Richterskalaen, som er en logaritmisk skala. Hvis styrken
stiger med 1, stiger den samlede energi i jordskælvet med
Gutenberg-Richter loven for jordskælv angiver forholdet mellem antallet af
jordskælv af forskellig styrke. I tabellen er dette
forhold angivet for de tre styrkeintervaller (med "b-value"
i Gutenberg-Richter loven sat til 1).
I opgaven her skal I kun betragte
de to første styrkeintervaller, 6.0-6.3 og 6.3-6.6.
Idet vi vil bruge data til at vurdere holdbarheden af
Gutenberg-Richter loven, skrives raterne i de to intervaller
som og eftersom en beregning viser,
at under Gutenberg-Richter loven (med "b-value" lig med 1) er
raten i det andet styrkeinterval halvt så stor som raten i det
første styrkeinterval. Enheden på er
antal forventede jordskælv per år.
Gutenberg-Richter loven svarer således til
hypotesen Lad os formulere situationen generelt gennem
modellen
hvor og er de stokastiske tælletal svarende til
de to styrkeintervaller. For at teste hypotesen kan man benytte følgende
teoretiske resultat. Hvis vi forestiller os, at er fast
(vi "betinger" med summen), så vil være binomialfordelt:
Hvis bliver
Et test for hypotesen kan derfor laves
som et test i binomialfordelingen for hypotesen, at
sandsynlighedsparameteren har værdien
I vores tilfælde bliver dette hypotesen, at
- Find -værdien for et test af hypotesen , for data i de to første rækker af tabellen ovenfor, ved at teste i modellen (1.10.1). Hvad bliver konklusionen af dette test ?
Opgave 1.6: Ændring i stormmønster
DMI vedligeholder en side med alle
storme i Danmark
fra 1891 og fremefter. Stormene kalssificeres i fire styrkekategorier ud fra
vindstyrken. I nedenstående tabel har jeg optalt antallet af storme
i de forskellige kategorier for fire 30-års perioder.
- Opstil den statistiske model, hvor antallet af storme for hver periode følger sin egen multinomialfordeling på de tre kategorier 1, 2 og 3+4. Angiv inden for den opstillede model hypotesen, at der er samme sandsynlighedsvektor for de tre styrkekategorier 1, 2 og 3+4 for de fire tidsperioder.
- Undersøg, om data er i overensstemmelse med hypotesen om samme sandsynlighedsvektor for kategorierne 1, 2 og 3+4 for de fire tidsperioder.
- Undersøg om fordelingen af hurricanes på de to styrkekategorier er den samme for de to tidsperioder.
- Opstil model for data, og undersøg, om fordeling på de fem verdenshave er den samme i de to perioder.
I opgave 10.5 i MSRR benyttes et datasæt fra artiklen
Corporate Social Responsibility and Workers’ Well-being in Nigerian Banks.
Forfatterne har spurgt 137 personer, der arbejder i banksektoren, om de
bruger de sundhedsmuligheder banken stiller til rådighed og om
sundhedstilbuddene er tilstrækkelige. Data er i følgende tabel
- Opstil en model for data i tabellen. Opstil dernæst en hypotese om sammenhængen mellem de to inddelingskriterier.
- Lav både -testet for den opstillede hypotese, såvel som permutationstetet og Fishers eksakte test. Kommenter på resultaterne.
Opgave 1.8: Betingning i poissonmodel
Lad , være
uafhængige stokastiske variable.
- Angiv fordelingen af .
- Find den betingede sandsynlighed Angiv i ord den betingede fordeling af givet at
I denne opgave skal I finde styrken af et test ved simulering.
I skal betragte modellen ,
uafhængige, og test af hypotesen
Styrken skal beregnes i tilfældet, hvor vi forkaster hypotesen,
når -værdien fra Resultat 1.6.1 er mindre end 0.05.
I kodevinduet nedenfor er vist det meste af den nødvendige kode.
ForegåendeNæste
- Indsæt de manglende argumenter i de to kald til rbinom. Henvis til formel i webbogen med hensyn til beregningen af likelihood ratio teststørrelsen qTest og indsæt den manglende kode for gTest. Indsæt den manglende kode i sum i den sidste linje for at beregne den simulerede styrke.
- Benyt koden til at finde ud af, hvor stor skal være, for at styrken er mindst 0.80 i tilfældet, hvor og