Afsnit 5.5: Datasæt med et stort antal forklarende variable
Near-infrared spectroscopy (NIRS) er en måleteknik, der benyttes
mere og mere i fødevareindustrien såvel som i mange andre områder.
Ideen er, at ved at sende lys af forskellige bølgelængder gennem en prøve
kan man få viden om sammensætning af prøven. For eksempel kan vi
være interesseret i at kunne vurdere mængden af fedtstoffer (respons)
i en prøve
ud fra lysabsorptionen ved en række forskellige bølgelængder.
Her er lysabsorptionen ved en bestemt bølgelænde en forklarende variabel,
og antallet af forklarende variable bliver det antal bølgelængde, som
der måles ved. Lysabsorptionen ved de forskellige bølgelængder kaldes
tilsammen
spektrum for prøven.
Som et konkret eksempel vil jeg se på brugen af NIRS til bestemmelse af
modenheden af frugter. Man ønsker at bestemme
Brix-værdien som er
et mål for den samlede mængde opløste faste stoffer
(TSS: total soluble solids), og som i frugt fortrinsvis er sukker.
Jeg benytter data fundet på
github, og som er data der bruges i
Daniel Pelliccia
blog og firmahjemmeside og vedrører sukkerindholdet i ferskner.
En tidlig beskrivelse af brugen af NIRS til analyse af ferskner kan findes
i artiklen
Determination of Sugar Content in Intact Peaches
by Near Infrared Spectroscopy
with Fiber Optics in Interactance Mode.
Datasættet har målinger på 50 ferskner, men jeg vil i dette afsnit kun bruge
de første 40 af disse. I afsnit
5.8 laver jeg prædiktion på de
sidste 10, og i afsnit
5.7
viser jeg hvordan analysen foregår i
R under brug af alle 50
målinger.
For de data vi betragter er lysabsorptionen målt ved 600
bølgelængder i området fra 1100-2300 nanometer.
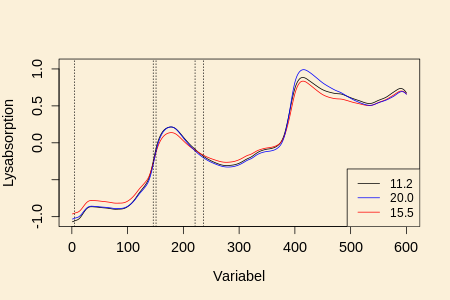
Figuren nedenfor viser spektrum for prøven med
mindst brixværdi (11.2), for prøven med størst
værdi (20.0)
og for en prøve med brixværdi midt mellem de to.
I det konkrete eksempel har vi således mange flere forklarende variable
end antallet af datapunkter. Dette gør det svært at konstruere en
multipel regressionsmodel. Hvis man prøver at lave regression
på alle variablene, vil man fitte en model, hvor alle de forventede
værdier bliver lig med de observerede responsværdier, og skønnet over
spredningen bliver
Man kan kalde dette en ekstrem grad af
"overfitting".
I en situation med mange forklarende variable kan vi således ikke
lave backward selektion til at reducere modellen. Jeg vil nu beskrive
en alternativ metode, kaldet
forward selektion,
til at etablere en model.
Ved forward selektion starter man med den mindst mulige model, det
vil sige modellen uden nogen forklarende variabel, hvor
alle de stokastiske variable har samme middelværdi.
Man bygger dernæst modellen op successivt, ved i hvert trin at
inkludere en ny forklarende variabel
baseret på en væsentlig reduktion i spredningsskønnet
Definition 5.5.1.
(Forward selektion)
I hvert trin prøver man på skift at inkludere en af de variable, der endnu
ikke er med i modellen. Fra parametertabellen,
for modellen med den ekstra variabel inkluderet, findes
spredningsskønnet og -værdien for test af hypotesen, at
regressinskoefficienten hørende til den ekstra variabel er nul.
Når alle variable er afprøvet, vælges den variabel med det
laveste spredningsskøn, og hvis den tilhørende -værdi er
under en selvvalgt grænse (for eksempel 0.05),
inkluderes variablen i modellen, og forward selektionsproceduren
fortsættes. Proceduren stopper, når -værdien for den valgte variabel
er over grænsen.
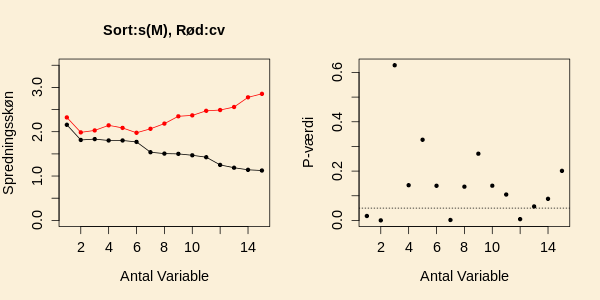
Figuren nedenfor viser resultatet af at lave forward selektion på
data omkring oktantal. Den sorte kurve i venstre delfigur viser
udviklingen af spredningskønnet
som funktion af
antallet
af forklarende variable, der er inkluderet i
modellen undervejs i forward selektion (den røde kurve forklares
senere). Den højre delfigur viser
-værdien for test af
, hvor
er
regressionskoefficienten for det sidst inkluderede led i modellen.
Figuren viser et fald i spredningsskønnet
når modellen udvides fra 1 variabel til 2 variable ved forward
selektion, og tilsvarende små
-værdier for test af, at
regressionskoefficienten for det sidst inkluderede led i modellen
er nul. For de næste fire variable er der næsten ingen fald i
, og
-værdierne ligger over 0.05. Med variabel 7 kommer der
igen et fald i
og en lille
-værdi. Dette mønster gentages
med de næste fem variable.
Bruger vi den formelle definition på forward selektion vil vi stoppe
efter at have medtaget to variable, hvor spredningsskønnet er 1.81.
Bruger vi i stedet syv variable er spredningskønnet 1.54.
Da variable i forward selektion udvælges ved at minimere
spredningsskønnet
, kan vi ikke regne med at dette skøn
giver et retvisende billede af variationen omkring middelværdimodellen.
Når vi har mange forklarende variable,
vil der også være en del, der ved rene tilfældigheder ser ud til at
være korreleret med respons, hvorfor disse inkluderes i modellen.
Der er således behov for en alternativ måde at lave et spredningsskøn på.
Den røde kurve i figuren ovenfor viser netop sådan en alternativ metode,
som bliver gennemgået i
næste
afsnit. Denne alternative metode peger på, at forward selektion med
seks variable er passende for disse data og giver et spredningsskøn
(eller rettere et skøn over prædiktionsfejl: se næste afsnit)
på 1.98. At der kun inkluderes seks variable afspejler også, at
vi kun har 40 prøver til rådighed
for at etablere modellen. Med flere prøver til rådighed vil det være
forventeligt, at forward selektion vil inkludere flere variable
(se afsnit
5.8).
ForegåendeNæste