Afsnit 1.7: Øvelse 1: IT
I denne opgave skal I ikke lave formelle test, men blot argumentere ud fra
jeres "mavefornemmelse".
- Under afprøvningen af et nyt mailsystem er der opstået 73 fejl fordelt på 13 områder som vist i den følgende tabel. Idet der i testperioden er brugt cirka lige meget tid på de forskellige områder, forventer vi den samme rate af fejl i hvert af de 13 områder. Er tallene i tabellen udtryk for den samme rate af fejl i de 13 områder ?
- Et hundrede studerende er blevet bedt om at teste to systemer (A og B) til netbaseret aflevering af opgaver. Af disse er der 61, der foretrækker system A, og 39, der foretrækker system B. Er dette et udtryk for, at system A er bedre end system B ?
- To programmører er blevet bedt om at lave den samme opgave. Efterfølgende er det konstateret, at den ene har lavet 4 fejl, og den anden har lavet 8 fejl. Er de to programmører lige omhyggelige ?
Når I skal køre R på jeres egen computer, bør I som hovedregel
ikke skrive jeres kommandoer direkte i kommandovinduet. I stedet skal I
åbne en editor, skrive kommandoerne her og derefter overføre dem til
kommandovinduet. På denne måde er det nemmere at rette fejl og at gentage
beregninger med forskelligt input. I windowsversionen af R
er der en indbygget editor, hvor I blot skal bruge control R
for at overføre markeret tekst (i Mac-versionen skal man i nogle
opsætninger bruge command enter i stedet). Som forberedelse til denne opgave skal I have læst
afsnit 1.2, der indeholder en
introduktion til R.
- Definer en variabel med værdien 4. Udregn kvadratroden af logaritmen af (naturlige logaritme) og eksponentialfunktionen af Lad endvidere være en variabel med værdien 10 og en variabel med værdien 1.96. Beregn Hvad tror du, at kommandoen n+c(-1,1)*x giver ?
- Lad være en vektor med indgangene og Beregn og ( er den naturlige logaritme). Numerisk værdi af et tal beregnes i R med funktionen abs.
- Lad være en vektor med indgangene og og lad være en vektor med indgangene og Beregn og
- Lad være vektoren med indgangene og lad være vektoren med indgangene Beregn og I den sidste sum skal der kun medtages de elementer i hvor det tilhørende element i er lig med 2. Lad nu være vektoren med indgangene "Lise", "Lise", "Peter", "Lise", "Peter", "Peter". Beregn Prøv at gætte på resultatet af beregningen sum(x[-c(4:6)]).
Denne opgave går ud på, at I skal prøve at lave en figur i R, som
beskrevet i afsnit R.5.
Til dette skal I bruge data, der er forsøgt lavet
i overensstemmelse med oplysningerne i artiklen
Dose-response associations between screen time and overweight among youth.
Det diskuteres ofte, om børn er i risiko for at blive overvægtige,
hvis de tilbringer meget tid foran fjernsynet eller computeren.
Data i tabellen nedenfor viser 303 piger fordelt på
fire kategorier i forhold til, hvor meget
tid de bruger foran skærmen. For hver kategori er der angivet,
hvor mange af pigerne der er overvægtige baseret på et taljemål.
Rækken med Tidsværdi reducerer tidsintervallet til en enkelt
værdi.
- Dan en vektor Tid med tidsværdierne, en vektor med antal piger i gruppen og en vektor over med antallet af overvægtige i gruppen. Dan ud fra disse vektoren logTid=log(Tid) med logaritmen til tiden, og dan en vektor frek med frekvensen af overvægtige, det vil sige antal overvægtige divideret med antal testede.
- Benyt kommandoen plot(logTid,frek) til at lave en figur, hvor frekvens afsættes mod logaritmen til tiden. Prøv at køre kommandoen igen, hvor du indsætter xlab="Log Tid" efter frek i kaldet af plot. Tilføj også en titel til andenaksen i figuren ved at tildele ylab en værdi i kaldet af plot. En overskrift til figuren kan opnås ved at indsætte main="overskrift" i kaldet af plot.
-
Funktionen, der sender over i
kaldes den logistiske dosis-respons funktion. Den bedste tilpasning til
data ovenfor fås med og For at indtegne
denne kurve i jeres figur kan I benytte kommandoen
curve(exp(-2.7560+1.3386*x)/(1+exp(-2.7560+1.3386*x)),
Funktionen curve skal som input have et funktionsudtryk i variablen et startpunkt og et slutpunkt. Tilføjelsen add=TRUE gør, at kurven indtegnes i den allerede eksisterende figur.Gentag plot-kommandoen, og prøv at tilføje col=2 til kaldet af curve. Prøv også at tilføje lty=3 til kaldet af curve.
from=-2,to=5,add=TRUE)
Opgave 1.4: Indlæse datafil i R (dataframe)
I denne opgave skal I prøve at indlæse data fra en fil. I filen
Trump.csv ligger for hver dag i uge 14 og hver dag i uge 16 i 2017
antallet af tweets skrevet af Donald Trump.
Filen har tre søjler. I den første står ugenummer, i den anden står
ugedag (søndag til lørdag (USA)), og i den tredje står antallet af tweets for den
pågældende dag.
- Indlæs filen, og placer indholdet i Trump, med kommandoen
Trump=read.csv("Trump.csv",header=TRUE,stringsAsFactors=TRUE)
Prøv at skrive head(Trump) for at se strukturen af denne. Kommandoen head giver de første få rækker i Trump. Skriv dernæst class(Trump). - Kommando class fortæller jer, at Trump er en dataframe. En dataframe er en samling af søjler, der alle har den samme længde, og hvor søjlerne kan være af forskellig type. Dataframe er det formelle navn i R, men jeg vil generelt omtale strukturen som en datatabel. Prøv nu både at skrive Trump[,3] og TrumpAntal. Dette viser, at en søjle kan hentes på to måder. Prøv også at skrive class(Trump[,3]). Dan en variabel Ugenr med ugenummeret (søjle 1), en variabel Dag med ugedagen (søjle 2) og en variabel Antal med antal tweets (søjle 3).
- Lav et datasæt med antal tweets for de 7 ugedage for
data fra uge 14 ved kommandoen
AntalUge14=Antal[Ugenr=="uge14"]
Lav tilsvarende et datasæt med antal tweets for uge 16. Find for hvert datasæt summen over de syv ugedage af antal tweets og det gennemsnitlige daglige antal for hver uge. - Du skal nu lave en ny datatabel med dine beregnede værdier
ved hjælp af funktionen data.frame. Kommandoen til at lave en
datatabel er på formen
data.frame(soejlenavn1=vektor1,...,soejlenavnk=vektork)
hvor vektor1 op til vektork er allerede eksisterende vektorer. Rækkenavne i tabellen kan indsættes ved at tilføje row.names=raekkenavne i kaldet til data.frame, hvor raekkenavne er en vektor med de ønskede navne. Lav en datatabel Mintabel med to rækker og to søjler, hvor søjleoverskrifter er Sum og Gennemsnit, og hvor en vektor med rækkenavne er givet ved c("uge14","uge16"). Når du har lavet datatabellen kan du udskrive denne ved blot at skrive navnet på tabellen, prøv dette.
Opgave 1.5: Sammenligne observerede med forventede
I menneske-maskine-interaktion betragtes
blandt andet, hvordan man flytter pointeren på en computerskærm via musen.
Figuren nedenfor viser en typisk opstilling, hvor en person
skal flytte pointeren fra område til område
I denne opgave skal I se på, om pointeren ender i venstre eller i
højre halvdel af målområde
Data er
stillet til rådighed af Jörg Müller.
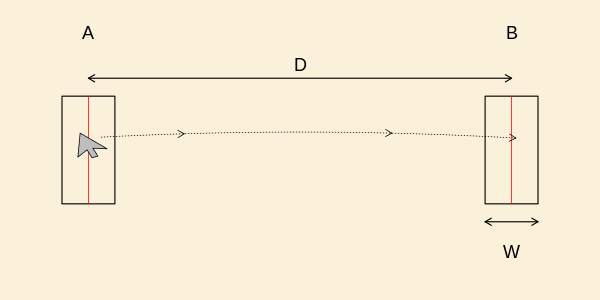 I den følgende tabel er vist resultatet fra to
eksperimenter, hvor forsøgspersonen i hvert eksperiment har
flyttet pointeren fra til 41 gange. I det første eksperiment er
bredden af målområdet og i det andet eksperiment er
bredden I begge eksperimenter er afstanden
mellem og givet ved
I den følgende tabel er vist resultatet fra to
eksperimenter, hvor forsøgspersonen i hvert eksperiment har
flyttet pointeren fra til 41 gange. I det første eksperiment er
bredden af målområdet og i det andet eksperiment er
bredden I begge eksperimenter er afstanden
mellem og givet ved
ForegåendeNæste
- Hvis pointeren ender et tilfældigt sted i målområde forventer vi, at det er tilfældigt, om endepunktet er i venstre eller i højre halvdel af Udtryk dette som et udsagn om sandsynligheden for at ende i venstre halvdel, og angiv de forventede antal svarende til de tomme pladser i ovenstående tabel for begge eksperimenter. Hvad er din umiddelbare vurdering: tyder data for eksperiment 1, med på, at det er tilfældigt, om pointeren ender i venstre eller højre halvdel ?
rbinom(Nsim,41,0.5)Denne kommando giver Nsim observationer fra en binomialfordeling med antalsværdi 41 og sandsynlighedsparameter
- Prøv at køre ovenstående kommando et par gange med Kør dernæst kommandoen med Lav en tabel ved hjælp af funktionen data.frame med tre søjler. Første søjle skal indeholde en vektor med de 20 simulerede værdier fra rbinom. Den anden søjle skal indeholde absolutværdien af afstanden mellem det simulerede antal og det forventede antal, Funktionen abs i R giver absolutværdien af et tal. Den tredje søjle skal være enten 0 eller 1, alt efter om er under eller er større end eller lig med denne værdi. Her er afstanden mellem det observerede antal på 8 og det forventede antal. Du kan benytte funktionen ifelse til at lave den tredje søjle: ifelse(D<12.5,0,1).
- Hvor mange af dine 20 simuleringer (som er baseret på en tilfældigt placering i venstre eller højre halvdel) giver anledning til en lige så stor eller større afstand end den, der er observeret i vores faktiske eksperiment ? Argumenter for, om observationen på 8 i venstre side er typisk eller atypisk, for hvad man observerer ved en tilfældig placering i venstre eller højre halvdel. Hvis du ikke allerede har gjort det, så læs nu Definition 1.1.1 på en -værdi, og se Resultat 1.4.1 omkring hvordan en -værdi bruges.