Afsnit 7.9: Øvelse 7: IT
Opgave 7.1: Flere regressionslinjer
I opgave 5.1 så I på udviklingen i antallet af transistorer på en chip
som funktion af årstallet. I denne opgave skal I se på tilsvarende data,
men nu delt op på fire producenter: ADM, Apple, IBM og Intel. I skal se på,
om der er forskel mellem de fire producenter, og i givet fald hvordan
kan forskellen beskrives. Data er i filen transist4Firmaer.csv, som indeholder tre søjler med
titlerne Transistorer, Aarstal og Producent.
- Indlæs data, og dan en vektor aar med årstal, en vektor logT med transformerede værdier af antallet af transistorer, og en faktor firma med producentnavnene. Lav en figur, hvor logT afsættes mod aar, og hvor hver producent har sin egen farve.
- Opskriv modellen, hvor middelværdien af LogT afhænger lineært af aar, og hvor hældning og skæring såvel som spredning omkring linjen afhænger af producent. Opskriv hypotesen, at de fire spredninger er ens, og lav et test af denne hypotese.
- Lav et qqplot af residualerne i modellen med samme spredning omkring regressionslinjen for de fire producenter.
- Undersøg, om det kan antages, at de fire hældninger er ens.Hvordan kan forskellen mellem de fire producenter beskrives i modellem med samme hældning ?
- Undersøg, om det kan antages, at de fire skæringer er ens i modellen med fælles hældning. Lav en parametertabel og lav 95%-konfidensintervaller for forskel i skæring mellem en producent og AMD. Giv en fortolkning af dine resultater.
Opgave 7.2: Multipel regression
I har i flere opgaver set på tidsforbruget ved at flytte en pointer
(en fysisk pegepind) ind i et målområde med bredde og
hvor afstanden fra start til midt af målområdet er
Opstillingen er vist i den følgende figur.
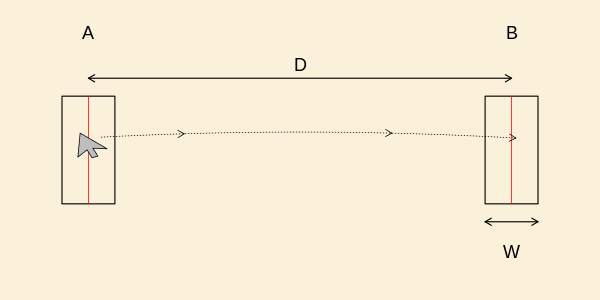 I opgave 1.5 og opgaverne 2.2-2.3 så I på, om slutpositionen af pointer
i målområdet er
symmetrisk i forhold til midtpunktet af målområdet, og i
opgave 3.3 så I, at fordelingen af slutpositionen
af pointer kan beskrives med en normalfordeling, og
testede i opgave 4.1 om fordelingen er centreret omkring midtpunktet. I opgave 4.2 lavede I en sammenligning mellem to eksperimentelle
opsætninger med forskellige værdier af Da der i denne type
eksperimenter er en stor variation mellem personer, så I i opgave 4.2 på
differencer for at fjerne personniveauet. Denne personeffekt betragtes
direkte i opgave 4.3. Endelig så I direkte på Fitts lov i opgave 6.3 i
specialtilfældet med fire forskellige værdier af og en fast værdi af Opgaverne 4.2 og 6.3 kan ses som en indledning til Fitts lov, som er emnet for
opgaven her.
I denne opgave skal I
bruge de oprindelige data fra Fitts artikel fra 1954:
The information capacity of the human motor system in controlling the amplitude of movement, publiceret i Journal of Experimental
Psychology. Eksperimentet er som vist i ovenstående figur.
Data i artiklen er gennemsnit af tidsforbruget for at flytte pointer
for 16 personer, der hver har lavet et stort antal gentagelser.
Vi kan derfor tænke på data som gennemsnit over 16 personværdier.
Fitts lov, som beskrives nedenfor, skal derfor ses som en relation
gældende for populationsgennemsnit og ikke nødvendigvis gældende på
individniveau. Fitt formulerede ikke direkte en lov, men skrev "We want to test the
hypothesis that movement times varies with task difficulty in such a
way that is constant over a wide range of movement amplitudes ()
and tolerances ()." Her er , hvor er
den målte tid. Som konklusion på de eksperimentelle resultater skriver
Fitt "that even though the index is not precisely constant, the hypothesis
is substantially confirmed." Et konstant indeks svarer til
en regression af på Andre forskere betragter i stedet
regression af på
I skal I denne opgave se, at denne regressionsmodel ikke er helt præcis (helt
i tråd med Fitts formulering), men alligevel fanger det meste af
variationen. I Fitts eksperiment er der 16 målinger i alt
svarende til alle kombinationer af fire afstande med
fire bredder Data findes i filen
FittsData.csv, der har
fire søjler. Afstand () og bredde () er angivet i tommer,
og tidsforbruget i millisekunder. Der er to søjler med tidsforbrug
svarende til to eksperimenter, hvor pegepinden, der flyttes, har
forskellig vægt, henholdsvis en "let" og
en "tung" pegepind. Figuren nedenfor viser tidsforbruget for den lette pegepind
afsat mod og farvekodet
efter værdien af (2,4,8,16: sort,rød,grøn,blå). For hver værdi af
er de fire punkter forbundet af et 2.grads polynomium (fundet ved
multipel regression med to forklarende variable og
) (modelformel: TG*logW+G*vWW,
hvor er en faktor, der inddeler efter værdien af ).
De fire stiplede kurver er fra regressionsmodellen
for alle data med den ene forklarende variabel
(modelformel TID). De stipledede kurver er den version af Fitts lov,
som vi betragter i denne opgave (og som giver et bedre fit til data
end regression på ). Som vi kan se, er Fitts lov ikke et
perfekt fit til data, men fanger alligevel det meste af variationen.
Dette er helt i overensstemmelse med Fitts egen formulering i den
oprindelige artikel.
I opgave 1.5 og opgaverne 2.2-2.3 så I på, om slutpositionen af pointer
i målområdet er
symmetrisk i forhold til midtpunktet af målområdet, og i
opgave 3.3 så I, at fordelingen af slutpositionen
af pointer kan beskrives med en normalfordeling, og
testede i opgave 4.1 om fordelingen er centreret omkring midtpunktet. I opgave 4.2 lavede I en sammenligning mellem to eksperimentelle
opsætninger med forskellige værdier af Da der i denne type
eksperimenter er en stor variation mellem personer, så I i opgave 4.2 på
differencer for at fjerne personniveauet. Denne personeffekt betragtes
direkte i opgave 4.3. Endelig så I direkte på Fitts lov i opgave 6.3 i
specialtilfældet med fire forskellige værdier af og en fast værdi af Opgaverne 4.2 og 6.3 kan ses som en indledning til Fitts lov, som er emnet for
opgaven her.
I denne opgave skal I
bruge de oprindelige data fra Fitts artikel fra 1954:
The information capacity of the human motor system in controlling the amplitude of movement, publiceret i Journal of Experimental
Psychology. Eksperimentet er som vist i ovenstående figur.
Data i artiklen er gennemsnit af tidsforbruget for at flytte pointer
for 16 personer, der hver har lavet et stort antal gentagelser.
Vi kan derfor tænke på data som gennemsnit over 16 personværdier.
Fitts lov, som beskrives nedenfor, skal derfor ses som en relation
gældende for populationsgennemsnit og ikke nødvendigvis gældende på
individniveau. Fitt formulerede ikke direkte en lov, men skrev "We want to test the
hypothesis that movement times varies with task difficulty in such a
way that is constant over a wide range of movement amplitudes ()
and tolerances ()." Her er , hvor er
den målte tid. Som konklusion på de eksperimentelle resultater skriver
Fitt "that even though the index is not precisely constant, the hypothesis
is substantially confirmed." Et konstant indeks svarer til
en regression af på Andre forskere betragter i stedet
regression af på
I skal I denne opgave se, at denne regressionsmodel ikke er helt præcis (helt
i tråd med Fitts formulering), men alligevel fanger det meste af
variationen. I Fitts eksperiment er der 16 målinger i alt
svarende til alle kombinationer af fire afstande med
fire bredder Data findes i filen
FittsData.csv, der har
fire søjler. Afstand () og bredde () er angivet i tommer,
og tidsforbruget i millisekunder. Der er to søjler med tidsforbrug
svarende til to eksperimenter, hvor pegepinden, der flyttes, har
forskellig vægt, henholdsvis en "let" og
en "tung" pegepind. Figuren nedenfor viser tidsforbruget for den lette pegepind
afsat mod og farvekodet
efter værdien af (2,4,8,16: sort,rød,grøn,blå). For hver værdi af
er de fire punkter forbundet af et 2.grads polynomium (fundet ved
multipel regression med to forklarende variable og
) (modelformel: TG*logW+G*vWW,
hvor er en faktor, der inddeler efter værdien af ).
De fire stiplede kurver er fra regressionsmodellen
for alle data med den ene forklarende variabel
(modelformel TID). De stipledede kurver er den version af Fitts lov,
som vi betragter i denne opgave (og som giver et bedre fit til data
end regression på ). Som vi kan se, er Fitts lov ikke et
perfekt fit til data, men fanger alligevel det meste af variationen.
Dette er helt i overensstemmelse med Fitts egen formulering i den
oprindelige artikel.
 De fittede 2.grads polynomier tilpasser 3 parametre til 4 dataværdier, eller
12 parametre til alle 16 dataværdier. Det er derfor ikke overraskende,
at vi ser meget lidt afvigelse mellem dataværdierne og kurverne. Alligevel
kan vi godt fornemme en systematik i kurverne: for er krumningen større
end for de andre tre kurver, og
absolutværdien af hældningen i punktet nul stiger med Hvordan kan
vi lave en beskrivelse, hvor både afhængigheden af og modelleres.
Det er naturligt at udvide polynomiet i til et polynomium i
både og , eller i som netop
er hvad I skal betragte i denne opgave.
De fittede 2.grads polynomier tilpasser 3 parametre til 4 dataværdier, eller
12 parametre til alle 16 dataværdier. Det er derfor ikke overraskende,
at vi ser meget lidt afvigelse mellem dataværdierne og kurverne. Alligevel
kan vi godt fornemme en systematik i kurverne: for er krumningen større
end for de andre tre kurver, og
absolutværdien af hældningen i punktet nul stiger med Hvordan kan
vi lave en beskrivelse, hvor både afhængigheden af og modelleres.
Det er naturligt at udvide polynomiet i til et polynomium i
både og , eller i som netop
er hvad I skal betragte i denne opgave.
- Indlæs data fra filen FittsData.csv, og dan de følgende variable: Dan endvidere variablen tidL med tidsforbruget med brug af den lette pegepind.
- Opskriv den multiple regressionsmodel, hvor middelværdien af tidsforbruget afhænger af alle ni forklarende variable ovenfor. Lav backward selektion på den multiple regressionsmodel (i denne proces fjerner I fire af de ni forklarende variable). Sammenlign skøn over spredningen i udgangsmodellen med alle ni variable og i slutmodellen med fem variable (til sammenligning er skøn over spredningen 7.31 i modellen, hvor der fittes et 2.grads polynomium for hver værdi af ).Lav også et -test for reduktion fra udgangsmodel til slutmodel.
- I skal lave en figur, hvor I indtegner slutmodellen som kurver i lighed med figuren ovenfor. Dette er ikke helt nemt, og følgende skjulte punkt giver vejledning til dette.
- Lav nu et -test for reduktion fra slutmodellen ovenfor til modellen med kun to forklarende variable logW og logDW. Sammenlign endvidere skøn over spredningen i de to modeller.
- Tag nu udgangspunkt i den multiple regressionsmodel med de to forklarende variable logW og logDW. Lav et test for at svarende til en regressionsmodel med kun en enkelt forklarende variabel Hjælp til dette: Erstat i den multiple regressionsmodel variablen logDW med variablen Den multiple regressionsmodel med de to variable logW og logDW er den samme model som den multiple regressionsmodel med de to variable logW og ID. I den sidste model skal I nu teste, at regressionskoefficienten hørende til logW er nul.
- Hvis du har lyst, kan du også prøve at se på data med den tunge pegepind.
I denne sidste afleveringsopgave er det meningen at I
hovedsageligt skal bruge metoderne fra de 6 første kapitler
af webbogen
(undtagelsen er det sidste spørgsmål). Data vedrører sammenhængen mellem CPU relative performance
(CPUrp, som først kan findes når produktet er på markedet)
og data omkring CPU-enheden,
der er til rådighed, før produktet bliver lanceret.
Til rådighed er der 6 egenskaber
Data er fra artiklen
Attributes of the performance of central processing units: a relative performance prediction model
og er hentet fra
UCI Machine Learning Repository.
Datasættet findes i filen CPUdata.csv, hvor de første seks søjler er
de forklarende variable omtalt ovenfor, søjle 7 er
CPU relative performance, og søjle 8 er en variabel, der inddeler data i
fem grupper.
Der er
207 rækker i filen svarende til 207 CPU-enheder
(hvor der i den oprindelige datafil optræder et nul, er dette ændret
til værdien 0.5 for at kunne logaritmetransformere data nedenfor).Indlæs data, og dan variablene logCT, logCA og
logCPUrp med logaritmen til de relevante variable. Dan desuden
variablene
og dan faktoren gr med værdierne i den sidste søjle
af de indlæste data.
Variabel logID, dannet ovenfor, er et indeks, der
modellerer sammenhængen mellem CPU relative performance
og de andre variable, og er fremkommet ved at
lave en multipel regressionsmodel for logCPUrp med
de forklarende variable logCT, logCA,
logMP, logMD, logCP og logCD.
Ved backward selektion finder man, at logCT,
logMD og logCD kan fjernes fra modellen. Gruppeinddelingen i faktoren gr er baseret på
værdierne af produktet logMP*logCA.
Benyt faktoren gr til at lave
to deldatasæt med logID-værdierne for grupperne og :
ForegåendeNæste
logIDa=logID[gr=="A"] og logIDd=logID[gr=="D"].
- For de 49 CPU-enheder i gruppe er der 10, der har en logID-værdi over 4. Opstil en statistisk model til beskrivelse af observationen 10, og lav et 95%-konfidensinterval for sandsynligheden, for at logID-værdien er over 4 i gruppe
- For de 53 CPU-enheder i gruppe er der 11, der har en logID-værdi over 4. Undersøg, om der er samme frekvens af CPU-enhder med en logID-værdi over 4 blandt grupperne og
- Opstil en statistisk model til beskrivelse af logID-værdierne i logIDa og logIDd. Lav et test for hypotesen, at der er samme middelværdi af logID-værdien i grupperne og .
- Betragt nu logID-værdierne for alle fem grupper dannet ud fra faktoren gr. Opstil en statistisk model for data, og undersøg først, om der er samme varians for de fem grupper, og dernæst, om der er samme middelværdi for de fem grupper.
- I det sidste spørgsmål skal I ikke længere betragte logID-værdierne, men derimod logCPUrp. Ovenstående analyse viser, at der er information i produktet logMP*logCA, der kan bruges til at beskrive logCPUrp. I dette delspørgsmål skal I analysere en multipel regressionsmodel til beskrivelse af logCPUrp, hvor I som forklarende variable bruger Giv navne til de 6 nye variable der består af produkt af to variable, og opskriv derefter den multiple regressionsmodel, hvor alle 9 forklarende variable inddrages.Reducer modellen ved brug af backward selektion, og lav grafisk kontrol af slutmodellen. Lav et test for reduktion fra startmodel til slutmodel, og angiv et 95%-konfidensinterval for regressionskoefficienten hørende til variablen logMP*logCA i slutmodellen.