Afsnit 7.4: Backward selektion
I en multipel regressionssituation ved man typisk ikke på forhånd,
at alle de forklarende variable indeholder information om respons.
Hvis man inkluderer mange variable, der ikke er relevante, kan dette
give et forkert billede af afhængigheden af de relevante variable,
og kan give et forkert indtryk af, hvor godt respons kan beskrives
(giver en for lille værdi af spredningsskøn
). Man taler i denne
sammenhæng om "overfitting". Hvis for eksempel man har
observationer, og man har
eller flere forklarende variable,
vil den multiple regressionsmodel give
og de forventede
værdier
er lig med de observerede værdier. Vores mål
må derfor være at finde en delmængde af de forklarende variable,
der giver en god beskrivelse af respons, og som ikke overfitter.
I en model med få forklarende variable er det nemmere at
fortolke modellen, og parametrene vil være bedre bestemt end
i en model med mange variable.
Jeg vil nu beskrive en metode til at reducere
den
fulde regressionsmodel (modellen, hvor alle de forklarende
variable er taget med) til en model med et færre antal
forklarende variable.
Ved
backward selektion fjerner man
successivt en af de forklarende variable
baseret på
-værdierne fra
-test af, at
regressionskoefficienterne er nul.
Definition 7.4.1.
(Backward selektion)
I hvert trin køres summary(lm(modelformel)) for den
aktuelle model. Den største -værdi blandt -testene, for at
en regressionskoeffcient er nul, identificeres. Hvis denne
-værdi er større end en selvvalgt grænse (for eksempel 0.05),
fjernes den tilhørende regressionsvariabel fra modellen.
Proceduren stopper, når ingen af -værdierne er over grænsen,
og den tilhørende model kaldes slutmodellen.
Typisk vil man også supplere testene med en registrering af
udviklingen af spredningsskønnet
i hvert trin, og til
sidst lave et
-test for reduktion fra startmodellen til
slutmodellen.
7.4.1 Eksempel
I dette eksempel vil jeg se på en beskrivelse af den globale
årstemperatur ud fra en række forklarende variable. Dette er
et emne, hvor man skal passe på med ikke at komme med
"amatørudsagn", og jeg støtter mig da også til fremstillingen
i artiklen
Using Data from Climate Science to Teach Introductory Statistics.
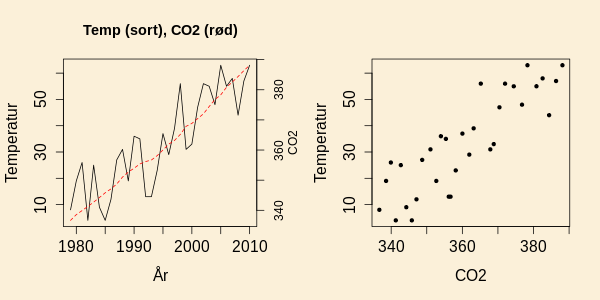
Figuren nedenfor viser den globale temperaturs
afvigelse fra et 30 års gennemsnit for årene 1979 til
2010 (afvigelse i grader celcius ganget med 100)
og udviklingen af co2 i atmosfæren i den samme periode
(ppm, parts per million).
Begge grafer viser et stigende forløb hen over perioden, og derfor
vil en regression af temperatur på co2 vise en tydelig sammenhæng,
som i højre delfigur nedenfor.
Spørgsmålet er, om der er andre effekter end co2, der kan forklare
temperaturstigningen
?
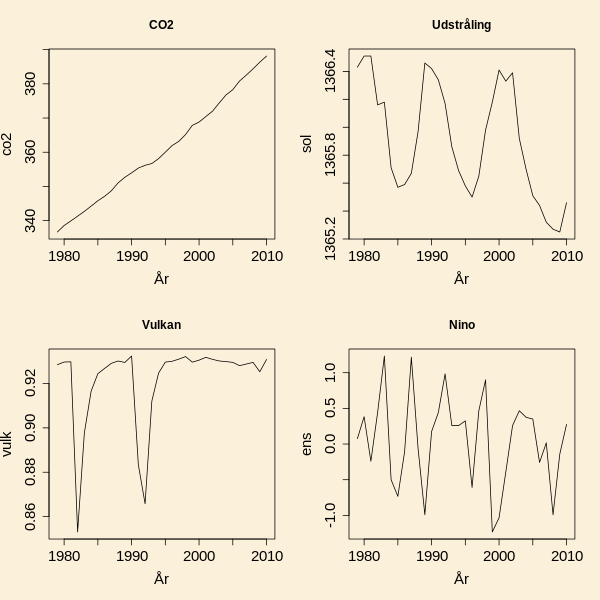
De kandidater, jeg vil inddrage, er solens udstråling
(solar irradiance, watt/
),
vulkanaktivitet og et mål for el Nino effekten.
Vulkanaktiviteten måles ved "MLO apparent transmission values",
som angiver den procentdel af solen udstråling, der rammer jordoverfladen, og
el Nino effekten måles som temperaturafvigelse i grader celcius.
I den næste figur
er de fire forklarende variable vist som funktion af tidspunkt.
Umiddelbart er der ikke nogen af de tre nye forklarende variable,
der viser en stigende eller faldende tendens hen over perioden,
men måske er der et sammenspil mellem dem, som ikke umiddelbart kan
ses. Dette kan vi få viden om ved at bruge en multipel
regressionsmodel.
Lad
være temperatur,
mængden af co2 i atmosfæren,
solens udstråling,
vulkanaktiviteten og
el Nino
effekten. Udover disse fire forklarende variable vil jeg også
inddrage interaktion mellem disse ved at medtage deres produkter,
hvor
,
,
og
er
standardiserede variable, det vil sige, at gennemsnit er trukket fra,
og der er divideret med empirisk spredning. For eksempel er
hvor
er den empiriske spredning for
variabel
Modellen, der analyseres, er
I den nedenstående kode analyseres modellen.
7.4.2 Multipel regression i R
Fra parametertabellen ses det, at
-test for
giver en
-værdi på 0.61,
og dette er den største
-værdi blandt de ti regressionsparametre.
Da denne
-værdi er langt over 0.05 fjerner vi leddet
VE
fra modellen. Kør det ovenstående program igen med
VE fjernet
fra modelformlen. Konstater, at
SE kan fjernes. Fortsæt på
samme måde og se at
CE,
CS og
CV kan fjernes.
I slutmodellen med multipel regression på
,
,
,
og
SV er
-værdierne for
test af de tilhørende regressionskoefficienter meget små pånær for
SV, og vi vælger ikke at reducere modellen yderligere.
Hvis man laver et
-test for reduktion fra den fulde model til
slutmodellem ved hjælp af kommandoen
anova(lmUD2,lmUD1), hvor
lmUD1 og
lmUD2 er output fra
estimationen af henholdsvis startmodel og slutmodel, får man en
-værdi på 0.21 (se afsnit
6.7 for beskrivelse af
anova).
I slutmodellen
er nedenfor gengivet parametertabellen fra kaldet
summary(lm(TC+S+V+E+SV)).
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.385e+04 5.734e+03 -4.158 0.000309 ***
C 1.055 0.089 11.859 5.45e-12 ***
S 16.771 4.125 4.065 0.000394 ***
V 638.117 157.559 4.050 0.000410 ***
E 9.063 1.824 4.967 3.66e-05 ***
SV -10.452 4.272 -2.447 0.021492 *
---
Residual standard error: 5.761 on 26 degrees of freedom
Det er usædvanligt, at med kun 32 datapunkter og med fem forklarende
variable at fire af disse er stærkt signifikante
(
-værdi langt under 0.05).
Regressionskoefficienten hørende til co2 (variablen C) ligger omkring 1,
hvilket betyder, at hvis mængden af co2 får lov til at stige med
100 ppm, så tyder denne meget simple model
på en stigning på 1 grad celcius i den
globale temperatur.
Datakilder
ForegåendeNæste