Afsnit 7.8: Prædiktion på nyt datasæt
For data omkring LOI-værdien i søsedimenter i afsnit
7.5 brugte jeg kun hver sjette indsamlede prøve.
Vi kan derfor bruge nogle af de resterende prøver
som et testsæt til at
vurdere den model, vi er kommet frem til. Nedenfor bruger jeg
hver 24-ende prøve, startende med nummer 3.
Hvor jeg i afsnit
7.6 beregnede en prædiktionsspredning
baseret på leave one out
crossvalidation, kan jeg her beregne en prædiktionsspredning
baseret på de 22 prøver i testsættet.
I kodevinduet nedenfor er vist
beregningen for data omkring LOI-værdien i tilfældet med
14 forklarende variable fra forward selektion.
Se opstartskoden (til/fra)
Når I kører koden, vil I se, at prædiktionsspredningen
fra det uafhængige testsæt er 5.6. Vi fandt tidligere
at prædiktionsspredningen fra crossvalidation var 8.6,
og spredningsskønnet
var 5.6. Resultatet her er
usædvanligt, normalt vil et testsæt give en
prædiktionsspredning, der er over
og mere
ligner resultatet fra crossvalidation.
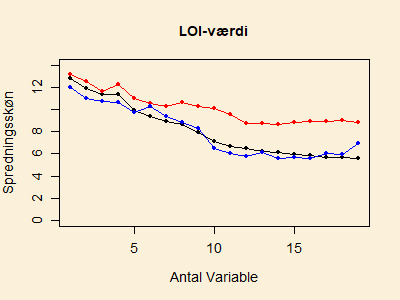
Figuren nedenfor viser den tidligere figur med spredningskøn
(sort)
og prædiktionsspredningen fra crossvalidation (rød), og hvor
nu også prædiktionsspredningen fra det uafhængige testsæt
er inkluderet (blå).
For data omkring LOI-værdien ser vi, at kurven (blå kurve) baseret
på testsættet med 22 prøver
generelt har et lidt overraskende forløb,
idet den ligger under den sorte kurve i starten og ellers følger
den sorte kurve.
Ideen med crossvalidation er at efterligne et uafhængigt testsæt,
hvorfor forventningen er, at den blå og røde kurve ville være
sammenlignelige. En formodning kunne være, at testsættet
ved en tilfældighed er meget tæt på træningssættet, men en beregning
viser det samme resultat, hvis testsættet består af alle de oprindelige
prøver, der ikke er medtaget i træningssættet (537-89 prøver).
Det ser ud til, at når træningsættet indeholder prøver fra alle 6
søer, så vil vores model være god til at prædiktere nye prøver
fra de samme søer. Omvendt, hvis en sø udelades fra træningssættet,
så kan vi risikere at prædiktionen ikke er så god.
Se i denne sammenhæng undersøgelserne i den oprindelige
artikel:
How well can near infrared reflectance spectroscopy (NIRS)
measure sediment organic matter in multiple lakes?.
ForegåendeNæste