Afsnit 7.5: Datasæt med et stort antal forklarende variable
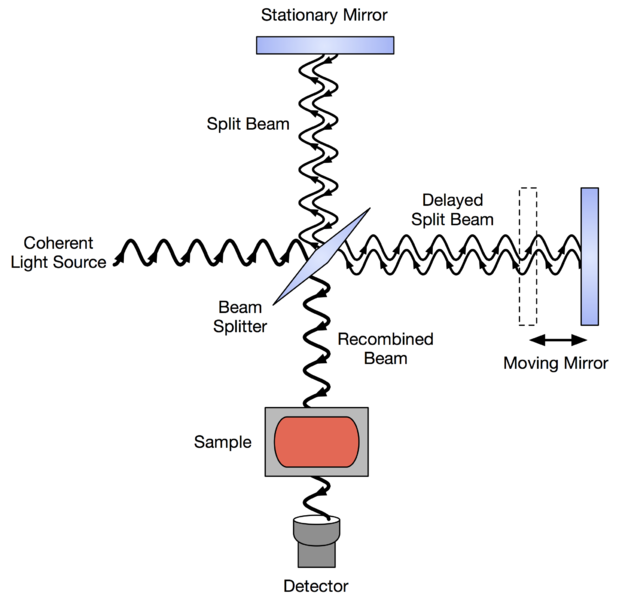
Near-infrared spectroscopy (NIRS) er en måleteknik, der benyttes
mere og mere såvel i industrien som i forskningssammenhænge.
Ideen er, at ved at sende lys af forskellige bølgelængder gennem en prøve
kan man få viden om sammensætning af prøven. For eksempel kan vi
være interesseret i at kunne vurdere mængden af fedtstoffer (respons)
i en kødprøve
ud fra reflektansen ved en række forskellige bølgelængder.
Her er reflektansen ved en bestemt bølgelænde en forklarende variabel,
og antallet af forklarende variable bliver det antal bølgelængde, som
der måles ved. Reflektansen ved de forskellige bølgelængder kaldes
tilsammen
spektrum for prøven.
Som et konkret eksempel vil jeg se på brugen af NIRS til bestemmelse af
mængden af organisk materiale i sedimenter på bunden af en sø.
Denne type undersøgelser kan blandt andet være af interesse for
studiet af klimaforandringer.
Mængden af organisk materiale måles som
Loss-on-ignition (LOI),
hvilket er en dyr og tidskrævende målemetode.
I artiklen
How well can near infrared reflectance spectroscopy (NIRS)
measure sediment organic matter in multiple lakes?
beskrives et eksperiment, hvor der er indsamlet data fra seks søer.
I dette afsnit vil jeg kun betragte en delmængde af de indsamlede data,
der fremkommer ved at medtage hver sjette prøve.
For hver prøve er NIRS spektrum målt ved 2151 bølgelængder
(i området 350-2500 nm).
For at gøre beregningsarbejdet mindre vil jeg dog kun betragte
hver 20-ende af disse, således at der er 107 bølgelængder til
rådighed. Data kan findes på følgende
dataverse-adresse.
Som nævnt, betragter jeg kun en delmængde af data, som indeholder 89 prøver.
Analysen af disse i
R vises i afsnit
7.7, og i
afsnit
7.8 benytter jeg den valgte model til
prædiktion på andre af de indsamlede prøver.
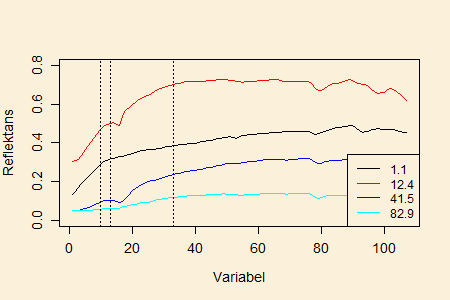
Figuren nedenfor viser spektrum for fire prøver hvori indgår
prøverne med den mindste og den største
LOI-værdi.
I det konkrete eksempel har vi således mange flere forklarende variable
end antallet af datapunkter. Dette gør det svært at konstruere en
multipel regressionsmodel. Hvis man prøver at lave regression
på alle variablene, vil man fitte en model, hvor alle de forventede
værdier bliver lig med de observerede responsværdier, og skønnet over
spredningen bliver
Man kan kalde dette en ekstrem grad af
"overfitting".
I en situation med mange forklarende variable kan vi således ikke
lave backward selektion til at reducere modellen. Jeg vil nu beskrive
en alternativ metode, kaldet
forward selektion,
til at etablere en model.
Ved forward selektion starter man med den mindst mulige model, det
vil sige modellen uden nogen forklarende variabel, hvor
alle de stokastiske variable har samme middelværdi.
Man bygger dernæst modellen op successivt, ved i hvert trin at
inkludere en ny forklarende variabel valgt således, at
spredningsskønnet
reduceres mest muligt.
Definition 7.5.1.
(Forward selektion)
Et trin i forward selektionsalgoritmen kan beskrives på følgende vis.
Antag, at den nuværende model har inkluderet variablene
(ved start af algoritmen er
).
For hver variabel prøver vi at udvide modellen med variabel
blandt de variable, der endnu ikke er inkluderet. Dette giver en
model med
variable, og for hvert
kan vi beregne et
spredningsskøn, som vi kalder
Den variabel
med mindst
spredningsskøn
er vores kandidat til udvidelsen af modellen.
I modellen hvor variabel
er inkluderet, kan vi se på
-værdien
for test af hypotesen
det vil sige, et test for at den sidst
inkluderede variabel kan undværes i modellen med
variable.
Alt efter størrelsen på denne
-værdi kan vi vælge at stoppe algoritmen.
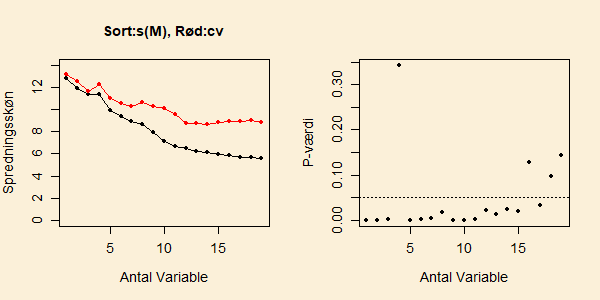
Figuren nedenfor viser resultatet af at lave forward selektion på
data omkring LOI-værdien i sedmenter fra søer. Den sorte kurve
i venstre delfigur viser
udviklingen af spredningskønnet
som funktion af
antallet
af forklarende variable, der er inkluderet i
modellen undervejs i forward selektion (den røde kurve forklares
senere). Den højre delfigur viser
-værdien for test af
, hvor
er
regressionskoefficienten for det sidst inkluderede led i modellen.
Figuren viser et kraftigt fald i spredningsskønnet
når modellen udvides fra 1 variabel til 3 variable ved forward
selektion, og tilsvarende små
-værdier for test af, at
regressionskoefficienten for det sidst inkluderede led i modellen
er nul. Når den fjerde variabel inkluderes falder
ikke og den
tilhørende
-værdi er langt over 0.05. Imidlertid falder
spredningskønnet igen kraftig, når den femte variabel inluderes.
Faldet i
fortsætter indtil 11 variable er inkluderet og
bliver derefter mindre. Ved 16 variable kommer
-værdien igen
over 0.05. Med 15 variable er spredningsskønnet 5.9.
Da variable i forward selektion udvælges ved at minimere
spredningsskønnet
kan vi ikke regne med at dette skøn
giver et retvisende billede af variationen omkring middelværdimodellen.
Når vi har mange forklarende variable,
vil der også være en del, der ved rene tilfældigheder ser ud til at
være korreleret med respons, hvorfor disse inkluderes i modellen.
Der er således behov for en alternativ måde at lave et spredningsskøn på.
Den røde kurve i figuren ovenfor viser netop sådan en alternativ metode,
som bliver gennemgået i
næste
afsnit. Denne alternative metode peger på, at forward selektion med
14 variable er passende for disse data og giver et spredningsskøn
(eller rettere et skøn over prædiktionsfejl: se næste afsnit)
på 8.6.
ForegåendeNæste