Afsnit 3.9: Øvelse 3: Geologi
Opgave 3.1: Goodness of fit test: Uniform fordeling
I 2009 publicerede Pieter Vermeesch en lille note med den provokerende
titel
Lies, damned lies, and statistics (in geology).
I noten betragter forfatteren
118415 jordskælv af styrke 4 eller over på Richterskalaen
i perioden 1/1-1999 til 1/1-2009 (data fra
earthquake.usgs.cov) og
fordeler disse på ugedag. Billedet her viser, hvor jordskælv optræder.
 Data kan ses i den følgende tabel
og findes i filen JordskaelvDag.csv fra opgave
1.4.
Data kan ses i den følgende tabel
og findes i filen JordskaelvDag.csv fra opgave
1.4.
- Opstil multinomialmodellen for disse data, hvor sandsynlighederne for at falde i de syv kasser er vilkårlige.
- Opskriv, inden for den opstillede multinomialmodel, hypotesen om ligelig fordeling på de syv ugedage. Udregn de forventede antal, og lav -testet for hypotesen. Hvad bliver konklusionen af testet ?
- Lav et -test for en ligelig fordeling, både for alle jordskælv med en styrke over 5 og for delmængden, hvor efterskælv er fjernet.
Opgave 3.2: Goodness of fit, poissonfordeling
Data i denne opgave vedrører positionen af kratere på
Mars.
Hvis kratere er spredt tilfældigt ud over Mars, vil antallet af kratere
i et område følge en poissonfordeling.
Data er hentet i
Mars Crater Database Search,
og vi betragter kun kratere med en diameter
over 4 km.
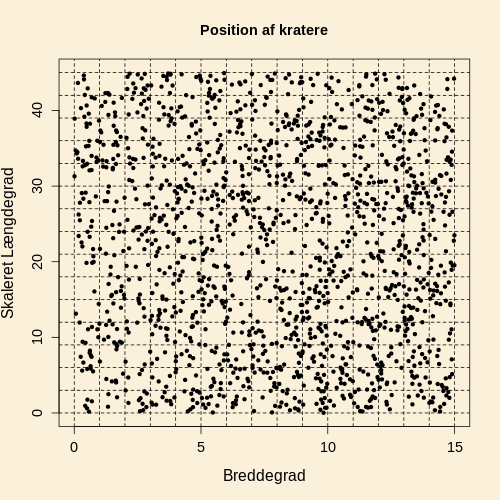
Området mellem 0 og 15 graders bredde
og 0 og 45 graders længde er delt op i områder af lige
stort areal. Dette er vist i den følgende figur, og
antallet af kratere i de 225 områder findes i filen KraterAntal.txt.
- Indlæs de 225 tællinger ved ordren nKrater=scan("KraterAntal.txt"). Lav et antalshistogram af data med intervalendepunkter endePkt=c(1:19)-0.5 (det første interval er fra 0.5 til 1.5, svarende til at den mindste værdi i nKrater er 1, og det sidste interval er fra 17.5 til 18.5, svarende til at den største værdi i nKrater er 18). Indsæt titler på akserne i figuren ved at benytte xlab og ylab i kaldet til hist. Placer antallet af observationer i hvert interval i en vektor antal. Vælg et af intervallerne ud, og eftervis antallet i antal ved en direkte optælling blandt de 225 dataværdier.
- Opskriv multinomialmodellen for den stokastiske antalsvektor Antal, hvor sandsynligheden for at falde i de forskellige kasser er vilkårlig.
- Opskriv, inden for din multinomialmodel, hypotesen om, at antallet af kratere i et område er poissonfordelt. Beregn de forventede antal under hypotesen. Hertil kan du benytte koden nedenfor. I R beregnes punktsandsynligheder i poissonfordelingen med dpois(x,lambda), og sandsynligheden for en værdi mindre end eller lig med beregnes med ppois(x,lambda). Forklar, at koden giver de forventede værdier. Indtegn de forventede antal i histogrammet fra spørgsmål (a) som en rød kurve med kommandoen lines(c(1:18),forvent,col=2), hvor forvent er vektoren med de forventede antal.
- Lav -testet for hypotesen, at antal kratere i et område er poissonfordelt. Slå kasser sammen, hvis de forventede ikke er større end 5 (slå kasser sammen fra hver sin ende, indtil det forventede antal er større end 5).Hvad bliver konklusionen af dit goodness of fit test ?
Opgave 3.3: Goodness of fit, normalfordeling
Data i denne opgave er mængden af krom i 61 prøver af vulkanske
lavabjergarter fra Ontario i Canada. Mængden af krom måles ved spektrokemiske
metoder. Data er fra artiklen
Minor element content of Ontario diabase.
I artiklen er 9 værdier blot angivet som større end 0.077.
I de data I skal bruge, er disse 9 værdier erstattet af simulerede værdier.
Data ligger i filen Ontario.txt.
Opgaven går ud på at lave et goodness of fit test for,
at kromindholdet kan beskrives med en normalfordeling.
- Indlæs de 61 mængder af krom (enheden er koncentrationsprocent)
fra filen Ontario.txt, placer disse
i vektoren krom, og dan vektoren logKrom=log(krom) med logaritmen
til mængden.
Lav et tæthedshistogram af data i logKrom med intervalinddelingen
endePkt=-8+c(0:13)*0.5.
Placer antallet af observationer i hvert
af de 13 intervaller i en vektor antal.Hvis logaritmen til mængden af krom
skal beskrives med en normalfordeling, er det bedste valg
af middelværdi og det bedste valg af spredning er
Indtegn normalfordelingstætheden i histogrammet med
kommandoen
curve(dnorm(x,-4.8961,1.6555),from=-8,to=-1,add=TRUE)
- Opskriv multinomialmodellen for den stokastiske vektor Antal, hvor sandsynlighederne for at falde i de forskellige intervaller er vilkårlige. Opskriv dernæst hypotesen, at sandsynlighederne for at falde i de 13 intervaller er givet ved sandsynlighederne for intervallerne i en normalfordeling med middelværdi og spredning Husk at i denne sammenhæng skal det første interval opfattes som intervallet fra minus uendelig til -7.5, og det sidste interval skal opfattes som intervallet fra -2.0 til uendelig. Beregn de forventede antal under hypotesen. Hertil kan du benytte koden nedenfor. I R beregnes sandsynligheden for en værdi mindre end eller lig med i en normalfordeling med kommandoen pnorm(x,,). Forklar, at koden giver de forventede værdier.
- Lav -testet for hypotesen, at kromindholdet er normalfordelt. Kan disse data beskrives med en normalfordeling ?
Data i denne opgave stammer fra rapporten
Stratigraphy, lithology, and sedimentary features of quaternary alluvial deposits of the South Platte River and some of its tributaries east of the Front Range, Colorado.
Der er indsamlet 100 sten fire steder i
South Platte River
flodløbet. (Overvej, hvordan man indsamler 100 tilfældige sten!)
Stenene er klassificeret efter litologi, og i denne opgave
vil vi kun betragte grupperne Gneiss, Pegmatite, Vein quartz og
Quartzite (hvorfor totaltallene i den følgende tabel
ikke er 100).
En eventuel forskel i fordelingen på litologi kan indgå i en
forståelse af de geologiske processer, der har formet floden.
- Opstil den statistiske model, hvor tælletallene for hvert område i Rocky Flats følger sin egen multinomialfordeling. Angiv inden for den opstillede model hypotesen, at der er samme sandsynlighedsvektor for kategorierne (Gneiss, Pegmatite, Vein quartz, Quartzite) for de to områder.
- Undersøg, om data er i overensstemmelse med hypotesen om samme sandsynlighedsvektor for kategorierne (Gneiss, Pegmatite, Vein quartz, Quartzite) for de to Rocky Flats områder (benyt eventuelt R-koden fra eksempel 3.7.2).
- Opstil en statstisk model for disse sum-data. Opskriv hypotesen, at der er samme fordeling på litologi for de to dele af flodsystemet, og lav et test for denne hypotese. Hvad bliver resultatet af dette test ?
Opgave 3.5: Poissonmodel med proportionale parametre
Lad os vende tilbage til data i
opgave 2.4 med tælletal
for antallet af jordskælv i tre styrkeintervaller. I opgaven her
betragtes kun de to første styrkeintervaller, 6.0-6.3 og 6.3-6.6.
Raterne i de to styrkeintervaller skrives som
og således at er
det forventede antal jordskælv per år.
Under Gutenberg-Richter loven (med "b-value" lig med 1) er
raten i det andet styrkeinterval halvt så stor som raten i det
første styrkeinterval, altså
- Opstil en poissonmodel til beskrivelse af eksperimentet, hvor rateparametrene og er som beskrevet ovenfor.
- Lav et test for hypotesen, svarende til Gutenberg-Richter loven, at raten i det andet styrkeinterval er det halve af raten i det første styrkeinterval (se Resultat 3.8.1).Hvad bliver konklusionen af dette test ?
DMI vedligeholder en side med alle
storme i Danmark
fra 1891 og fremefter. Stormene kalssificeres i fire styrkekategorier ud fra
vindstyrken. I nedenstående tabel har jeg optalt antallet af storme
i de forskellige kategorier for fire 30-års perioder.
ForegåendeNæste
- Opstil den statistiske model, hvor antallet af storme for hver periode følger sin egen multinomialfordeling på de tre kategorier 1, 2 og 3+4. Angiv inden for den opstillede model hypotesen, at der er samme sandsynlighedsvektor for de tre styrkekategorier 1, 2 og 3+4 for de fire tidsperioder.
- Undersøg, om data er i overensstemmelse med hypotesen om samme sandsynlighedsvektor for kategorierne 1, 2 og 3+4 for de fire tidsperioder.
- Undersøg om sandsynlighedsvektoren for de to styrkekategorier er den samme for de to tidsperioder.
- Opstil model for data, og undersøg, om sandsynlighedsvektoren for fordelingen af kategori 4-5 hurricanes på de fem verdenshave er den samme i de to tidsperioder.