I indledningen til kapitel
5 viste jeg en figur,
hvor indbyggerantal voksede med antallet af storkepar.
Jeg omtalte det i kapitel 5 som
spurious correlation.
Man kan også udtrykke det på den måde, at det er vigtigt i en
analyse af data at have inkluderet alle de relevante variable.
Lad mig vise dette med et mere realistisk eksempel end
eksemplet med storkepar. Datasættet
swiss
i
R
indeholder data omkring fertilitet i 47 kommuner i den fransktalende del af
Sweitz fra omkring 1888 (oprindelige kilde til data kan ses ved at
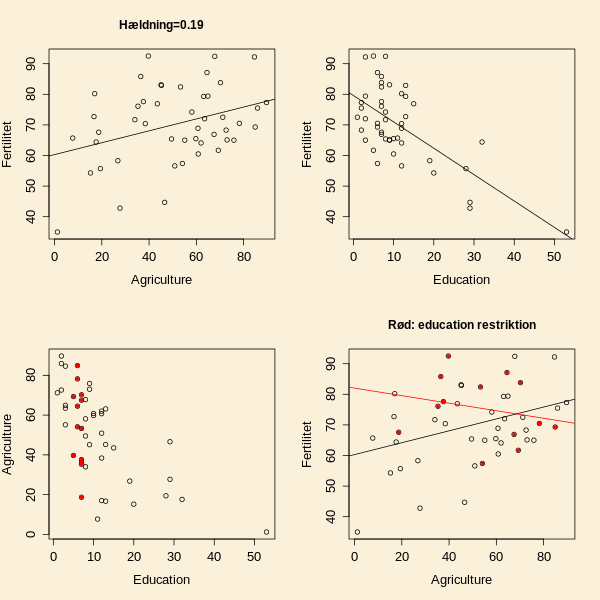
følge ovenstående link). Hvis man afsætter fertiliteten mod
procentdelen af befolkningen, der er beskæftiget i landbruget
(
agriculture), ses
en positiv sammenhæng med en regressionskoefficient på 0.19
(
-værdi for at teste regressionskoefficienten lig med nul er 0.015).
Afbildes i stedet fertiliteten mod procentdelen
af befolkningen med en uddannelse (
education),
viser figuren en negativ sammenhæng.
De to situationer er vist i de øverste delplots i figuren nedenfor.
Laver vi en model, der tager hensyn til begge variable, en såkaldt
multipel regressionsmodel som bliver indført i
afsnit
7.3, viser det sig, at regressionskoefficienten hørende
til
agriculture nu er -0.07
(
-værdi for at teste regressionskoefficienten lig med nul er 0.41).
At vi kan gå fra en regressionskoefficient på 0.19 til -0.07 skyldes en
stærk korrelation mellem
agriculture og
education, som vist
i det nedre venstre delplot.
Når vi tager hensyn til både
education og
agriculture, kan
man tale om afhængigheden af
agriculture for fastholdt værdi af
education. For at illustrere dette har jeg udvalgt data med en
værdi af
education mellem 4 og 8 og lavet regression af
fertilitet på
agriculture for de udvalgte data.
De udvalgte data er vist med rødt i det nedre venstre delplot, og
den tilhørende regressionslinje er vist i det nedre højre delplot.
Det ses tydeligt i figuren, at afhængigheden af
agriculture
er anderledes når
education holdes fast.
For 130 år siden havde folk i landbruget ikke nogen særlig uddannelse, og
det er derfor naturligt, at en høj procentdel af uddannede peger på en lav
procentdel inden for landbruget. Da der også har været en tendens til at
uddannede får færre børn, må der være en sammenhæng mellem procentdel
uddannede og fertiliteten. Når analysen tager hensyn til dette, kan
vi ikke længere se en effekt af andelen, der arbejder i landbruget.
I dette kapitel ser jeg på to måder til at inddrage ekstra viden i en
regressionssituation. Først ser jeg på situationen med en kategorisk
variabel (en faktor), der inddeler data i undergrupper. For at undersøge
indflydelsen af denne variabel ser vi på modellen, hvor hver gruppe
har sin egen lineære sammenhæng mellem middelværdi af respons og
den forklarende variabel i regressionsmodellen. Modellen
indføres i afsnit
7.1, og et eksempel analyseres i
afsnit
7.2.
Dernæst ser jeg på situationen med flere forklarende variable, der kan
bruges til beskrivelse af respons, som i fertilitetseksemplet ovenfor.
Modellen indføres i afsnit
7.3, og i afsnit
7.4 diskuterer jeg, hvordan man kan vælge en delmængde af de
forklarende variable til at danne en slutmodel for data.
Den sidste del af kapitel 7 handler også om den multiple regressionsmodel,
i situationen hvor der er et meget stort antal forklarende variable,
der kan bruges til at beskrive respons. Mange målemetoder indført gennem
de sidste 30-50 år måler simultant et stort antal værdier knyttet til den
samme prøve. Et eksempel, som bruges i
7.5, er et
near-infrared spektrum,
hvor reflektionen af lys måles simultant ved et
stort antal bølgelængder. Et andet eksempel er
microarray målinger,
hvor aktivitetsniveauet måles simultant for et stort antal gener
i en celleprøve. Et tredje stort område er scanningsbilleder i
diagnostiske medicinske sammenhænge.
Vi skal kun berøre et lille hjørne af dette
emne, nemlig hvordan man kan undgå "overfitting" ved at
bruge
crossvalidation til at vurdere, hvor godt modellen beskriver
data. Dette beskrives i afsnit
7.6. Jeg har lavet nogle programmer i
R, der gør det nemt for jer at "lege" med disse ting.
Programmerne beskrives i
7.7.
ForegåendeNæste