Afsnit 7.3: Den multiple regressionsmodel

7.3.1 Den multiple regressionsmodel
Statistisk Model 7.3.1.
(Den multiple regressionsmodel)
I den multiple regressionsmodel betragter vi
uafhængige stokastiske variable
og middelværdien af respons er en
linearkombination af forklarende værdier.
Analysen af den multiple regressionsmodel laves med følgende
kommandosummary(lm(xt1+t2++td))hvor, i den konkrete situation, skal erstattes af navnet på responsvariablen, og t1,t2,td skal erstattes med navnene på de forklarende variable, og summen af de led skal skrives fuldstændigt ud. I parametertabellen fra summary er Intercept skønnet over og skønnet over den 'te regressionskoefficient står ud for navnet på den 'te forklarende variabel (her tj). Den 'te forventede værdi er og skønnet over variansen i modellen er idet middelværdimodellen har parametre. Ligesom for den simple regressionsmodel i afsnit 5.5 kan vi være interesseret i middelværdien for givne værdier af de forklarende variable. Skønnet over denne, kaldes den prædikterede værdi. Et konfidensinterval for beregnes i R med predict (med indstillingen interval="confidence") som i afsnit 5.5, hvor der så skal bruges en dataframe
nyData=data.frame(t1=td=)Som i afsnit 5.5 kan man få et prædiktionsinterval i stedet, det vil sige et interval for en kommende observation, ved at lave indstillingen interval="prediction" i kaldet til predict.
Eksempel 7.3.2.
(Flytte computermus)
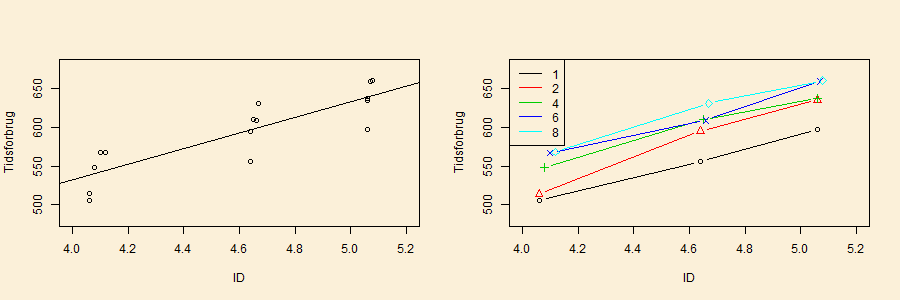
I det følgende kodevindue analyseres datasættet omtalt ovenfor omkring
tidsforbruget ved at flytte computermus ind i et målområde.
Lad tid være tidsforbuget (gennemsnit over 10 personer
og 24 gentagelser), ID index of difficulty og
lad være response entropy. Modellen, der analyseres, er
hvor kan variere frit.
Kør koden.
De estimerede regressionskoefficienter er henholdsvis
99.2 og 20.6, og begge har stor betydning for beskrivelsen af
tidsforbruget (meget små -værdier, når man tester
koefficienten lig med nul). Skønnet over spredningen er 7.9. Da de målte værdier ligger omkring
500 til 600 svarer dette til en procentvis spredning på
lige lidt over 1 procent.
Hvis vi kun laver regression på index of difficulty ID,
bliver spredningsskønnet 25.2. Dette kan formulers på den
måde, at inddragelsen af response entropy reducerer
spredningen til under en tredjedel. Det næste kodevindue laver plots af residualer mod henholdsvis
ID og og et normalt qqplot.
Lad os afslutte dette eksempel med at lave prædiktion af
tidsforbruget for to nye opgaver med værdierne
Det følgende kodevindue laver konfidensintervaller for
middelværdien af tidsforbruget for de to opgaver.
ForegåendeNæste
Kør koden. Kan du forklare, hvorfor det andet konfidensinterval er
bredere end det første ?
Ændr koden, så der beregnes
prædiktionsintervaller i stedet.
Den første af de to nye opgaver ligger midt i området for data, hvor
middelværdien er velbestemt, hvorimod den anden opgave ligger i
udkanten af dataområdet. For at lave et prædiktionsinterval skal man erstatte "confidence" med
"prediction" i koden.