Afsnit 1.7: Introduktion til konfidensinterval
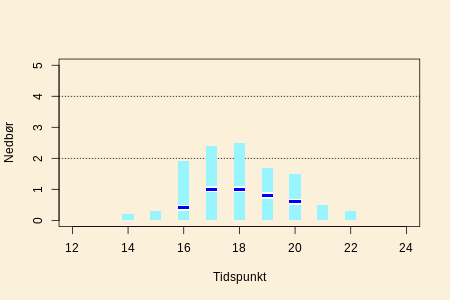
På DMI's hjemmeside angives en nedbør til tider som en lyseblå
lodret bjælke med en mørk blå streg omkring midten af bjælken.
Den mørkeblå streg angiver det "bedste" skøn over nedbøren.
Den lyseblå bjælke er sat på for at vise, at skønnet over
nedbøren er usikker. Alle nedbørsmængder inden for bjælken
anses for realistiske for, hvad nedbøren vil blive på det
pågældende tidspunkt. DMI beskriver det på følgende måde:
"For nedbør vises usikkerheden som lyseblå søjler med den mest
sandsynlige værdi markeret som et mørkeblåt bånd."
I resten af kapitel 1 vil jeg beskrive, hvordan man ud fra indsamlede data og en
statistisk model til beskrivelse af disse kan lave skøn over de
parametre, der indgår i modellen.
Jeg starter i afsnit
1.8 med et generelt princip for,
hvordan man beregner et skøn over en parameter i en statistisk model.
Som i nedbørssituationen vil et skøn i sig selv indeholde for
lidt information. For at illustrere det på anden vis, hvis vi for eksempel
får at vide, at 50%
blandt voksne jydske mænd foretrækker rugbrød frem for
franskbrød til morgenkaffen, så er det vigtigt at vide, om dette skøn
er baseret på, at man har spurgt to personer eller baseret på, at man
har spurgt 200 personer.
Vi kan sige det kort på den måde, at når skønnet betragtes
som en stokastisk variabel, er der brug for at kende spredningen
på denne, det vil sige, hvad er spredningen, hvis vi forestiller os,
at undersøgelsen gentages mange gange (med nye personer hver gang).
I stedet for at fokusere på spredningen vil vi ligesom
i nedbørseksemplet angive usikkerheden ved at konstruere et interval af
parameterværdier, der alle kan bruges til at beskrive data.
Dette formuleres gennem et
konfidensinterval i
afsnit
1.9. Fortolkningen af et konfidensinterval
illustreres gennem et simuleringseksperiment i
afsnit
1.10.
I første omgang illustrerer jeg konfidensinterval med binomialmodellen
og udvider dernæst dette til poissonmodellen i
afsnit
1.12 og med et gennemregnet eksempel
i afsnit
1.13. Afsnit
1.12
forklarer, hvordan man kan se poissonmodellen som en beskrivelse
af hændelser, der kommer tilfældigt i tid.
Afsnit
1.11 er et teknisk afsnit, hvor jeg
meget kort giver baggrunden for formlen, der bruges til at lave
et konfidensinterval i binomialmodellen.
ForegåendeNæste