Afsnit 3.9: Øvelse 2
Opgave 2.1: Teste uniform fordeling
I ethvert eksperiment bør man overveje reproducerbarhed af resultaterne.
I denne opgave skal I se på dette i form af, om fordeling af molekyler på
en overflade er uniform. Overfladen er dannet ved, at en polymerfilm
er blevet overtrukket med en tynd opløsning af fluorescerende molekyler
efterfulgt af spincoating. Den uniforme fordeling er en form for
reproducerbarhed, en anden ville være, om gentagelse af eksperimentet ville
give den samme mængde af molekyler per areal.
Data i opgaven her er simulerede, men inspireret af laboratorieøvelsen
beskrevet i
The Poisson Distribution and Single-Molecule Spectroscopy. An Undergraduate Analytical Laboratory ExperimentEfter behandlingen af overfladen er denne scannet med et
fluorescensmikroskop. Tre lige store områder vælges ud og antallet af
molekyler tælles. I alt er der talt 217 molekyler, og disse fordeles på
de tre områder som vist i den følgende tabel.
- Opstil en statistisk model for fordelingen af de 217 molekyler på de tre områder. Angiv, med modellens parametre, hypotesen, at molekylerne er uniformt fordelt over overfladen.
- Lav et test for hypotesen om en uniform fordeling af molekylerne.
Opgave 2.2: G-test med en parameter
Denne opgave vedrører det samme eksperiment som i opgave
1.7 omkring registrering af enkelte molekyler ved hjælp af
en nanopore sensor. I opgaven skal I betragte ventetiden på
ankomst af et molekyle. Data er ventetiden for 261 molekyler
fordelt på intervallerne (sekunder) , , ,
og større end 4. Af de 261 ventetider er der 104 med en værdi mellem 0 og 1,
som vist i tabellen nedenfor.
Data er fundet ved en aflæsning fra figur 3 i
Calibration-Free Nanopore Digital Counting of Single Molecules
(tallet 261 er ikke opgivet, men fundet ved at bruge en opgivet usikkerhed).
I artiklen bruger forfatterne ventetiderne som tjek på at molekylerne
kommer tilfældigt i tid. Hvis dette er tilfældet,
forventer vi, at ventetiden mellem
2 molekyler følger en såkaldt eksponentialfordeling,
og det er dette, der illustreres i figur 3 i artiklen.
Eksponentialfordelingen er beskrevet ved en parameter således at
sandsynligheden for en ventetid mellem og er
og sandsynligheden for en
ventetid større end er Hvis et skøn over findes som beskrevet i afsnit 3.3,
baseret på antallene i ovenstående tabel, får man
- Opstil en statistisk model for data i tabellen ovenfor, og angiv med modellens parametre hypotesen om, at ventetiderne kan beskrives med eksponentialfordelingen.
- Lav et test for hypotesen om eksponentialfordelte ventetider (angiv resultat i bogen, der bruges til testet, angiv forventede, og angiv om betingelse for at bruge -test er opfyldt, og forklar antallet af frihedsgrader i den -fordeling der bruges).
Opgave 2.3: Goodness of fit, poissonfordeling
Data i denne opgave tager udgangspunkt i forsøg med
bakterieceller, hvor man ofte har behov
for at tælle, hvor mange af
disse man har i en given opløsning. Dette gøres ved at udtage en
mindre del af opløsningen og tage billede af denne i et mikroskop, hvor
bakterierne så kan tælles. Et eksempel på et sådant billede er vist
nedenfor, hvor de små sorte områder er
enkelte
E. coli
bakterier. De store områder i midten af billedet er
hver på og her inden for tælles antallet
af bakterier.
For at sikre konsistens
tælles en bakteriecelle, der ligger ind over en kant, kun med hvis det er
den venstre eller den øverste kant, der berøres.
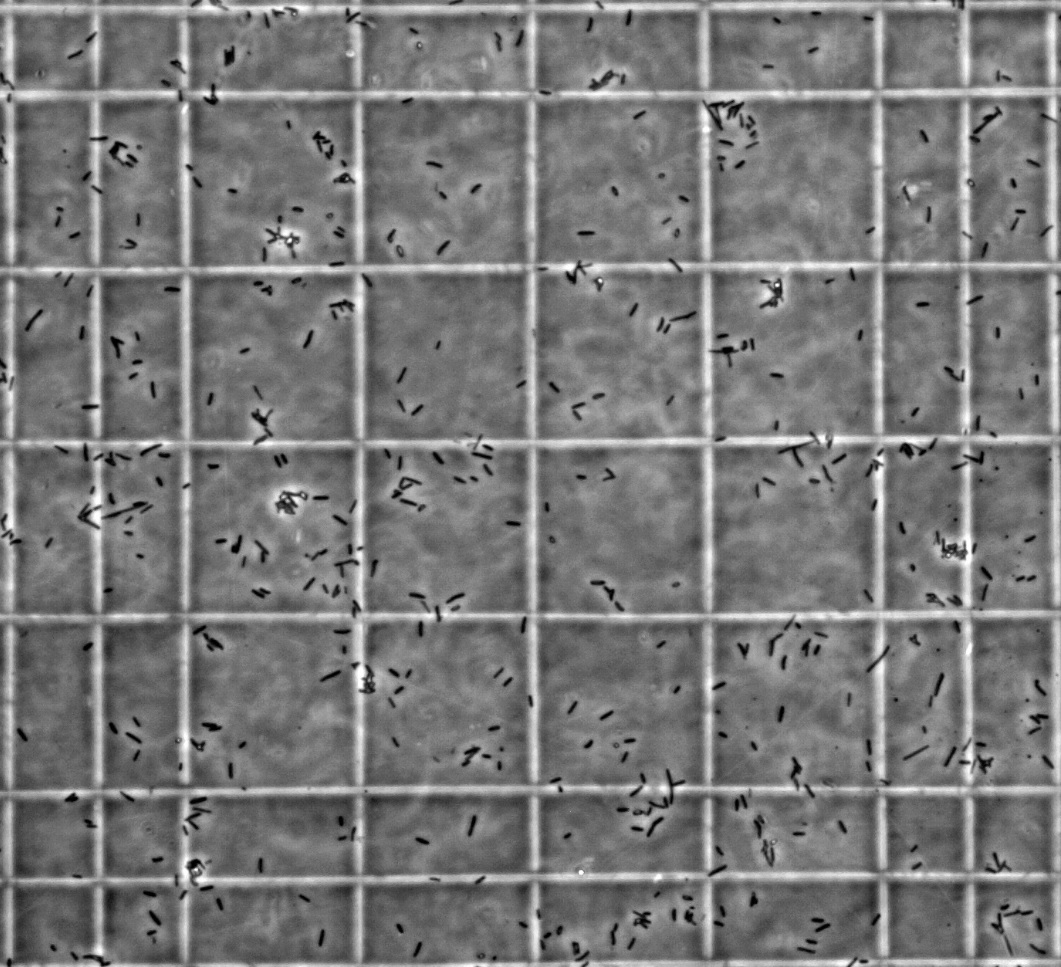 I filen CelleData.txt ligger
data fra optælling fra
14 sådanne billeder, hver med 16 områder. Data er indsamlet
med henblik på opgaven her og stillet til rådighed af
Morten Bormann Nielsen.
I filen CelleData.txt ligger
data fra optælling fra
14 sådanne billeder, hver med 16 områder. Data er indsamlet
med henblik på opgaven her og stillet til rådighed af
Morten Bormann Nielsen.
- Læs de 224 kvadrattællinger ind i en vektor
nColi (se indlæsningskommandoer i afsnit
1.6). Lav et antalshistogram af data med intervalendepunkter
givet ved vektoren
endePkt=np.array([0,9,11,13,15,17,19,21,23,32])-0.5
Indsæt titler på akserne i figuren. Beregn antallene af observationer i de 9 intervaller med endepunkter i endePkt (svaret er gengivet i tabel nedenfor). - Opstil en statistisk model for de stokastiske variable svarende til observerede antal
- Det antages ofte, at tælletal af typen i denne opgave er poissonfordelte (tælletallene her er de 224 tal svarende til antallet af bakterier i de 224 kvadrater). Opskriv, i modellen fra foregående spørgsmål, hypotesen om, at de underliggende 224 tælletal er udfald fra en poissonfordeling med parameter
- Hvis et skøn over findes som beskrevet i afsnit 3.3, baseret på antallene får man De forventede værdier i de 9 kasser (intervaller) kan ses i følgende tabel. Beregn det forventede antal i kasse 6 med fire decimaler. Udfør -testet for hypotesen om, at tælletallene kan beskrives med en poissonfordeling (hypotesen om, at antal bakterier i et kvadrat er poissonfordelt).
- Hvad bliver konklusionen af dit goodness of fit test ? Kan du komme med en formodning om, hvad der ligger bag ved resultatet ?
- Hvis I sammenligner de ni observerede antal med de ni forventede antal, vil I se, at data spreder sig mere ud end forventet under en poissonfordeling. Man bruger ofte ordet overspredning for at beskrive situationen. En måde at tænke på dette på er, at hvert bakterieantal er poissonfordelt, men raten varierer fra område til område på de 14 billeder. Når tælletal som her viser overspredning, prøver man ofte at beskrive data med den negative binomialfordeling. Denne fordeling har to parametre, en sandsynlighedsparameter og en formparameter og er givet ved hvor brøken er lig med 1 når I python udregnes fordelingsfunktionen (sandsynlighden for en værdi mindre end eller lig med ) med kommandoen st.nbinom.cdf(x,kappa,p).Følgende tabel viser de forventede under antagelsen om, at bakterieantallene er negativ binomialfordelte. Synes I, at den negative binomialfordeling giver et godt fit til bakteriantallene ?
Opgave 2.4: Homogenitetstest: dambrug
I dambrug kan vandet indeholde smags- og duftforbindelser
(taste and odor compound: TOC), der optages i
fisken og nedsætter dens værdi. Det er omkostningsfyldt at analysere
en fisk både ved en kemisk analyse og ved sensorisk måling (vurdering af
et smagspanel). Omvendt er det nemmere at analysere vandet i dambruget,
og det er derfor af interesse, om der er en klar forbindelse mellem
indholdet af TOC i vandet og fiskens tilstand.
Tabellen nedenfor viser resultatet af en sensorisk analyse for
fisk fra dambrug med forskelligt indhold af geosmin
(organisk forbindelse med en jordlugt) i vandet.
Smagspanelet vurderer
fisken på en såkaldt muddy-skala, og i tabellen er angivet antallet af
fisk under og over 3 på denne skala.
Der er undersøgt 50 fisk fra dambrug med et lavt indhold af
geosmin (), 74 fisk fra dambrug med et
middelindhold af geosmin (), og
25 fisk med et højt indhold af geosmin ().
Data stammer fra
Chemical and sensory quantification of geosmin and 2-methylisoborneol in Rainbow Trout (Oncorhynchus mykiss) from Recirculated Aquacultures in Relation to Concentrations in Basin Water..
Her er først en multiple choice opgave. Nedenfor er der 1 eller 2
korrekte svar. Find disse.
- Homogenitetshypotesen er ikke relevant her, da der kun er to søjler (to kategorier for opdeling af data).
- For at vurdere om vi har tiltro til homogenitetshypotesen bruges Resultat 3.7.1.
- Homogenitetshypotesen er ikke relevant her, da der er flere end 2 rækker i tabellen.
- Hvis der er 2 forventede værdier under 5 bruger vi ikke -testet.
- Opstil en statistisk model for tælletallene fra de tre grupper af dambrug.
- Angiv, inden for den opstillede model, hypotesen at der er samme fordeling på kategorierne Under og Over for de tre grupper af dambrug.
- Undersøg, om data er i overensstemmelse med hypotesen formuleret i foregående spørgsmål.
- Beregn også den alternative teststørrelse Bliver -værdien fra denne teststørrelse større eller mindre end -værdien fra foregående spørgsmål ?
Opgave 2.5: Uniform fordeling af p-værdier
I afsnit 1.3 er det nævnt, at selvom en hypotese er sand, så
vil vi i cirka 5 procent af tilfældene få en -værdi mindre end eller
lig med 0.05. Mere generelt gælder der, at når hypotesen er sand, så
vil -værdien, betragtet som stokastisk variabel,
approksimativt fordele sig uniformt over
intervallet fra 0 til 1. Dette skal I grafisk
se på i denne opgave baseret på
simulerede data. I kodevinduet nedenfor simuleres nSim -værdier
i en binomialmodel, og der laves et tæthedshistogram med inddeling
i intervallerne , , , og
Hvis -værdierne fordeler sig uniformt, vil højden af
kasserne i tæthedshistogrammet ligge omkring 1.
- Hvilken binomialfordeling simuleres der fra ? Hvilken hypotese testes ?
- Kør koden nogle gange. Er resultaterne som forventet, specielt for intervallet ?
- Ændr nu det simulerede antal fra 1000 til 100000, og kør koden nogle gange.
- Ændr dernæst til . Kommenter på figuren.
- Ændr pHyp=0.7 til pHyp=0.5, og kør først tilfældet med og dernæst Sandsynligheden for at få en -værdi under 0.05, når hypotesen der testes ikke er sand, kaldes styrken af testet. Højden af kassen i histogrammet i intervallet afspejler styrken, når der testes , og den sande værdi af er 0.70.
Opgave 2.6: Sammenligne to poissonrater
Et laboratorie er inddelt i to grupper af medarbejdere. I den første
gruppe er der 12 medarbejdere og i anden gruppe er der 8 medarbejdere.
I løbet af et år er der 39 pipetteglas der er gået i stykker i gruppe
1 og 18 i gruppe 2.
- Opstil en poissonmodel til beskrivelse af eksperimentet, hvor rateparametrene og for de to grupper angiver det forventede antal (i et år) per medarbejder.
- Opskriv hypotesen, at der ikke er forskel mellem de to grupper.
- Lav et test for hypotesen, at der er samme rate i de to grupper (se Resultat 3.8.1).Hvad bliver konklusionen af dette test ?
Opgave 2.7: Homogenitetstest: kirale krystaller
I artiklen
Enantioselectivity switch in chiral crystallization
using optical trapping with gold nanoparticles
beskrives, hvordan man længe har forsket i forklaringer på, at
kirale molekyler typisk kun optræder i en af de to former.
Blandt andet har man undersøgt effekten af polariseret lys,
uden dog at komme frem til et klart svar. Artiklen kigger i stedet på
krystaller, der bliver belyst med polariseret lys under
dannelsen. For at fremme dannelsen af krystallerne tilsættes
guldnanopartikler (AuNP) af forskellig størrelse.
I artiklen siger forfatterne, at "The most striking and significant finding
of this study is the observation that the enantioselectivity of the
crystallization process reverses for larger AuNPs."
I skal se på data nedenfor til belysning af dette udsagn. I skal først se på krystaller frembragt, når der bruges guldnanopartikler
af størrelse 10 nm og 60 nm (som begge er under den grænse, hvor processen
"reverses"). Tabellen nedenfor giver, hvor mange krystaller af D og L-form der
er dannet.
- Opstil en statistisk model for tælletallene fra de to eksperimenter med forskellig strørrelse af guldnanopartiklerne (husk, at angive det "Statistisk Model" nummer, der bruges).
- Undersøg, om data er i overensstemmelse med hypotesen om samme sandsynlighed af D-form i de to eksperimenter.
- Anvend nu data fra rækken "Samlet" i ovenstående tabel, og lav et 95%-konfidensinterval for sandsynligheden for D-form.
- Benyt nu de to rækker med samlede tal fra de to tabeller til at lave et test af hypotesen om samme sandsynlighed for D-form blandt eksperimenter med små guldnanoartikler i forhold til eksperimenter med store guldnanopartikler.
- Forklar, at resultatet af dine undersøgelser stemmer overens med udsagnet fra artiklen nævnt i starten af denne opgave.
- P-værdien kan ikke beregnes, da den ene af de forventede værdier er over 5.
- Hvis -værdien for test af homogenitet er over 1, har vi tiltro til hypotesen.
- Frihedsgradsantallet for den approksimative -fordeling for -teststørrelsen for test af homogenitet er .
- Hvis -værdien for test af homogenitet er under 1, har vi tiltro til hypotesen.
Opgave 2.8: Afleveringsopgave 1
I forbindelse med besvarelsen af denne opgave skal du downloade filen
svarAflevering1.txt fra kursushjemmesiden og indsætte nogle tal
fra din besvarelse som angivet nedenfor. Filen skal afleveres sammen med din
pdf-fil med besvarelsen.I artiklen Statistical Modeling and Analysis for Robust Synthesis of Nanostructures)
beskrives et eksperiment hvor fremkomsten af tre nanostrukturer
(nanosaws, nanowires og nanobelts) studeres. For hver deleksperiment
betragtes 180 områder og disse klassificeres som en af de tre strukturer
(eller ingen struktur). I artiklen ønsker man at modellere sandsynligheden
for hver af de tre strukturer som funktion af tre kontrolvariable:
temperatur, tryk og afstand mellem kilde og substrat hvor strukturerne dannes.
Hvis vi for eksempel betragter antallet af nanosaws ønsker forfatterne at
beskrive en observation som udfald fra en binomialfordeling med antalværdi
180 og en sansynlighedsparameter Den fittede funktion
forfatterne finder har værdien for en
temperatur på 750, tryk på 200 og afstand på 16.4. I skal i opgaven her se at ovenstående skitserede model ikke kan fange
al den variation der findes i data. Nedenstående tabel viser data fra to
deleksperimenter der begge har værdierne af temperatur, tryk og afstand
som nævnt ovenfor.
- Opstil en statistisk model til beskrivelse af deleksperiment 1. Overfør bogens Statistisk Model nummer til svarAflevering1.txt.
- Undersøg, om data er i overensstemmelse med hypotesen, at sandsynligheden for en nanosaw i deleksperiment 1 er Overfør -værdien fra dit test, med tre decimaler, til svarAflevering1.txt.
- Betragt nu deleksperiment 2 og lav et 95%-konfidensinterval for sandsynligheden for en nanosaw. Overfør den øvre grænse i konfidensintervallet, med tre decimaler, til svarAflevering1.txt.
- De 92 nanosaws er tilfældigt fordelt på overfladen af substrat, og er derfor et udfald fra en poissonfordeling.
- Hver af de 180 undersøgte strukturer kan enten være nanosaws eller noget andet, og de 92 nanosaws er derfor et udfald fra en binomialfordeling.
- For at undersøge hypotesen at der er lige stor sandsynlighed for at få en nanosaw som at få noget andet, bruges resultat 3.7.1
- Da 92 er større end , forkastes hypotesen, at sandsynligheden for en nanosaw er .
- Hvis -værdien er mindre end , for et test af hypotesen at sandsynligheden for en nanosaw er , forkastes hypotesen.
Opgave 2.9: Dosis-respons, figur
I et dosis-respons eksperiment testes effekten af et stof ved
forskellige doser. For hver dosis
testes individer, og
der registreres, at af disse reagerer. Den relevante model er
binomialmodellen (samme som multinomialmodellen med kasser)
hvor er antallet af forskellige doser der testes. Tabellen nedenfor viser resultatet af et eksperiment med
forskellige doser.
- Lav for hver dosis et 95%-konfidensinterval for
- Oversæt de fundne konfidensintervaller til konfidensintervaller for parameteren (kaldes log-odds).
- Lav en figur, hvor skøn afsættes mod dosis Indsæt i figuren lodrette linjestykker, svarende til konfidensintervallet for log-odds for hver dosis.
- Beskriv den sammenhæng, du ser i figuren mellem log-odds og dosis.
Opgave 2.10: Dosis-respons, test
Betragt situation og data som i foregående opgave (opgave 2.9).
Idet binomialmodellen er ækvivalent med multinomialmodellen med kasser
kan vi skrive data som
De forventede i den logistiske dosis-responsmodel er
for
Hvis man fitter den logistiske
dosis-responsmodel til data, bliver skøn over de to parametre
- Lav et test for at data kan beskrives med den logistiske dosis-responsmodel (se afsnit 3.8.1 for metoden).
Opgave 2.11: Konfidensinterval for andel
Betragt data fra opgave 2.1 ovenfor, hvor 217 molekyler fordeles på
tre områder.
- Lav et 95%-konfidensinterval for andelen af molekyler der falder i område 1.
Opgave 2.12: Sammenhæng i poissondata
Antal jordskælv af en given styrke inden for et givet tidsrum og
et givet geografisk område beskrives ofte med en poissonmodel.
I tabellen nedenfor er jordskælv i New Zealand i perioden 1930-2015
(i alt 86 år)
for tre styrkeintervaller på Richterskalaen.
- Lav for hvert styrkeinterval et 95%-konfidensinterval for raten af jordskælv per år.
- Oversæt de fundne konfidensintervaller til konfidensintervaller for logaritmen til raten per år, det vil sige parameteren
- Lav en figur, hvor skøn afsættes mod midtpunktet af styrkeintervallet. Indsæt i figuren lodrette linjestykker, svarende til konfidensintervallet for logaritmen til raten for hvert styrkeinterval.
- Beskriv den sammenhæng, du ser i figuren mellem logaritmen til raten og midtpunktet af styrkeintervallet.
Opgave 2.13: Teste log-lineær sammmenhæng i poissondata
Dette er en fortsættelse af opgave 2.12. Det samlede antal jordskælv
i de tre styrkeintervaller er 138. Hvis vi forestiller os, at vi holder
det samlede antal fast på 138, kan vi (og det skal I i denne opgave)
betragte de observerede antal som et udfald fra en
multinomialfordeling med kast af en generel tresidet terning. Hvis er raterne fra opgave 2.12, og er
midtpunktet for det 'te interval, er vi interesseret i at teste en
lineær sammenhæng,
I multinomialmodellen, der opstår, når vi holder fast, svarer dette
til hypotesen
Den bedste værdi af til beskrivelse af data er
ForegåendeNæste
- Lav, i multinomialmodellen, et test af denne hypotese.