Afsnit 9.3: Datasæt med et stort antal forklarende variable
Near-infrared spectroscopy (NIRS) er en måleteknik, der benyttes
mere og mere i fødevareindustrien såvel som i mange andre områder.
Ideen er, at ved at sende lys af forskellige bølgelængder gennem en prøve
kan man få viden om sammensætning af prøven. For eksempel kan vi
være interesseret i at kunne vurdere mængden af fedtstoffer (respons) i en prøve
ud fra lysabsorptionen ved en række forskellige bølgelængder.
Her er lysabsorptionen ved en bestemt bølgelænde en forklarende variabel,
og antallet af forklarende variable bliver det antal bølgelængde, som
der måles ved. Lysabsorptionen ved de forskellige bølgelængder kaldes
tilsammen
spektrum for prøven.
Som et konkret eksempel vil jeg se på
oktantallet i 60 bensinprøver, hvor lysabsorptionen er målt ved 401
bølgelængder i området fra 700-2500 nanometer. Spektrumsmålingen er
hvor
er målingen af den diffuse reflektion.
Data er oprindeligt fra artiklen
Two Data Sets of Near Infrared Spectra. I kodevinduet nedenfor hentes data fra en
GitHub-adresse.
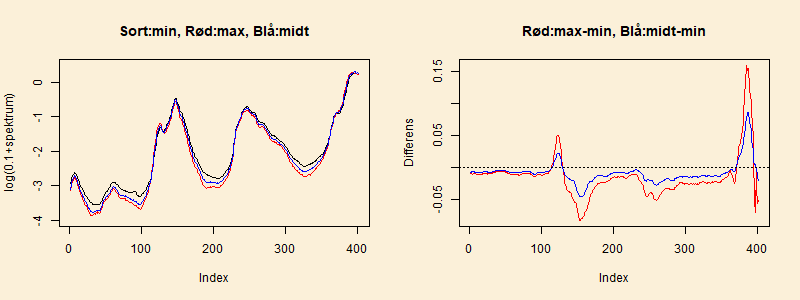
I det venstre delplot af den følgende figur vises
spektrum for prøven med det mindste oktantal (83.4), for prøven med
det største oktantal (89.6),
og for en prøve med oktantal midt mellem de to (86.6).
Der er brugt en transformation af spektrumsværdien for bedre at kunne
se forskel mellem de tre spektre. Desuden viser den højre delfigur
differens mellem to spektre, henholdsvis mellem spektre for
det største og mindste oktantal og mellem spektre med en mellemværdi og
med den mindste værdi af oktantallet.
I det konkrete eksempel har vi således mange flere forklarende variable
end antallet af datapunkter. Dette gør det svært at konstruere en
multipel regressionsmodel. Hvis man prøver at lave regression
på alle variablene, viser det sig, at der er uendelig mange løsninger
, hvor alle de forventede værdier
,
er lig med de observerede værdier
og dermed at spredningsskønnet bliver
.
Man kan kalde dette en ekstrem grad af "overfitting".
I figuren i afsnit
9.5 er vist en af disse løsninger
(
er afsat mod
i form af en stiplet linje),
der er valgt således, at
er mindst mulig.
Figuren viser en meget kraftig variation i
for at opnå, at de forventede er lig med de observerede.
Hvordan får vi lavet en simpel beskrivelse af data, hvor vi har undgået at
"overfitte"
? Jeg vil her vælge den tilgang, at det primære formål med
undersøgelsen er at lave en model, der er god til at prædiktere værdien
af kommende observationer. Man kan sige, at vi så bevæger os væk fra
traditionel statistisk inferens og hen mod
machine learning.
Jeg vil i de kommende afsnit beskrive to metoder til at bygge en model.
For begge metoder gælder, at vi ikke kan anvende sædvanlige variansskøn
til at vurdere kvaliteten af modellen. I den første metode
vil jeg bygge modellen op nedefra og successivt tilføje flere og flere
led. Dette giver god mening, hvis vi har en formodning om, at der kun er
et mindre antal af de forklarende variable, der har reel betydning
for middelværdien af respons. Men hvor mange led skal vi inkludere i
modellen
? I den anden metode beholdes alle de forklarende variable,
men vi lægger begrænsning på, hvor meget de skønnede regressionsparametre
må variere. Problemet her er at finde ud af, hvor meget begrænsning vi skal
indføre.
Som mål for hvor god en model er til at prædiktere, vil jeg indføre en
prædiktionsspredning. Denne skal være af typen "root mean squared
error of prediction" (RMSEP). Dette kan nemmest beskrives, hvis
vi først forestiller os, at vi har både et
træningssæt og
et
testsæt af data. Træningssættet har
datapunkter
,
og
ud fra disse bestemmes skønnene
Testsættet har
datapunkter, som vi betegner
,
For det
'te element i testsættet er
prædiktionsfejlen
hvor
er den prædikterede værdi,
Prædiktionsspredningen, betegnet med
bliver nu
9.3.1 Cross-validation
Problemet i ovenstående tankegang med et træningssæt og et testsæt
er, at man typisk
ikke har et nyt sæt observationer, der kan bruges som testsæt.
I stedet deler vi det oprindelige datasæt op i to dele og bruger
disse som træningssæt og testsæt.
Typisk laver man flere forskellige opdelinger
i træningssæt og testsæt, for at testsættet kommer rundt i
hele det oprindelige datasæt.
Dette kendes under navnet
cross-validation
(
krydsvalidering på dansk).
Lad mig først prøve at beskrive cross-validation abstrakt. Vi har
datapunkter og ønsker at evaluere en estimationsmetode.
Cross-validation kan beskrives gennem følgende punkter.
- Del på tilfældig vis data op i et træningssæt og et testsæt.
- Gennemfør estimationsmetoden på træningssættet, og find
skøn over de parametre, der indgår i modellen.
- Lav for hver prøve i testsættet en prædikteret værdi ud
fra de forklarende værdier hørende til prøven og parameterskønnene
fra foregående punkt. Beregn dernæst prædiktionsfejl som
responsværdi minus den prædikterede værdi.
- Gentag punkt 1-3 med andre inddelinger i træningssæt og testsæt,
således at de forskellige testsæt kommer rundt i hele datasættet.
- Beregn prædiktionspredning som kvadratroden af
gennemsnit af de kvadrerede prædiktionsfejl.
I
Leave one out cross-validation (LOOCV) lader man testsættet
bestå af kun en enkelt observation, og træningssættet er de
resterende
observationer. Dette gentager man
gange,
hvor i det
'te trin observation nummer
udgør testsættet.
Hvis vi lader
betegne den prædikterede værdi for
den
'te observation, når træningssættet består af alle
observationerne pånær den
'te, kan vi skrive cross-validation skønnet
over prædiktionsspredningen som
I
-fold cross validation deler man datasættet op i
cirka lige store dele, og hver del er så efter tur testsættet.
Opdelingen er tilfældig og kan eventuelt gentages en række
gange. I denne bog vil jeg kun bruge LOOCV.
ForegåendeNæste