Afsnit 2.5: Opgave med besvarelse: levetid af overfladebobler

Eksempel 2.5.1.
(Besvarelse)
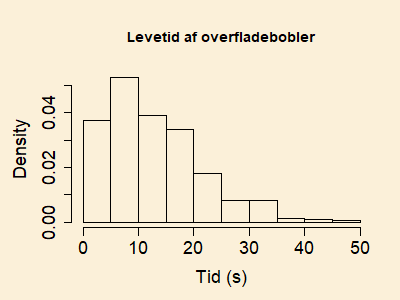
Idet den største værdi i data er 45.1, laver vi intervalinddelingen
Antallene i de
forskellige intervaller betegnes
og findes i Python med kommandoen hist,
se kodevinduet nedenfor.
For de tilhørende
stokastiske variable bruges Statistik Model 2.1.1,
Vi ønsker at teste hypotesen
hvor er fordelingsfunktionen for en weibullfordeling.
Fra opgaveformuleringen vides, at skønnene over de ukendte parametre er
og De forventede
kan derfor beregnes som
Fra beregningen i kodevinduet får vi de observerede (første række)
og forventede
(anden række med 1 decimal):
ForegåendeNæste
Kasse 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Obs 40 64 72 80 59 51 61 42 32 19 7 15 16 7 3 2 1 2 2 Forv 39.7 66.3 74.2 73.1 66.8 58.0 48.3 38.8 30.3 23.0 17.1 12.4 8.8 6.1 4.2 2.8 1.9 1.2 2.0For at få alle de forventede større end eller lig med 5 slås kasse 15 og 16 sammen såvel som kasserne 17, 18 og 19. Dette giver de observerede antal 4 og 5, og de forventede antal 7.0 og 5.1. Efter denne sammenlægning er der 16 kasser, hvorfor antallet af frihedsgrader i -fordelingen bliver 16-1-2=13, idet vi under hypotesen har to frie parametre ( og ). -teststørrelsen for vores hypotese beregnes fra formlen hvor og er de observerede og forventede, efter at kasser er slået sammen. Beregningen i kodevinduet viser, at og den tilhørende -værdi er Da -værdien ligger lidt over 0.05, siger vi at data ikke strider mod hypotesen om, at levetiderne af overfladeboblerne er weibullfordelt.
2.5.2 Beregning i Python af goodness of fit
Koden nedenfor indeholder en del linjer, der er specifikke for det
konkrete eksempel, der betragtes. Alle steder, hvor weibullfordelingen bruges,
er naturligvis specifikke, såvel som intervalinddeling og
sammenlægning af intervaller for at opnå, at de forventede er store nok.
Disse steder er markeret i kommentarerne med "eksempel".
Udover beregningen af goodness of fit testet indtegnes også
weibulltætheden i histogrammet. Bemærk i koden brug af np.delete og
np.append.