Afsnit 9.7: Øvelse 7
Opgave 7.1: Multipel regression
Formålet med data i denne opgave er at prædiktere, hvor god en
kemisk forbindelse er til at bremse BTK (Brutons Tyrosine Kinase).
Respons er , hvor
er half maximal inhibitory concentration,
det vil sige den mængde, der er nødvendig for at nedsætte
BTK aktiviteten til det halve ( skal angives i
mol/L før logaritmen beregnes). Bemærk, at en stor værdi af
betyder større evne til at bremse BTK.
Hvis man ud fra simple beskrivelser af den kemiske forbindelse kan
prædiktere , kan man benytte dette til at designe nye
forbindelser eller til at løbe gennem et bibliotek af
kemiske forbindelse for at finde gode kandidater til at bremse BTK. Data i denne opgave er en delmængde af data fra
Computational regression and prediction analysis on a dataset of 52 Pyrrolo[2,3-b]Pyridines and Pyrimidines Rheumatoid Arthritis inhibitors.
Vi vil betragte fire variable til beskrivelse af :
molekylevægten af den kemiske forbindelse (MW),
logaritmen til partition coefficient (logP),
antal hydrogenbindinger i acceptorgruppe (HBA)
og måling foretaget ved røngtenspektroskopi (KA1).
Forfatterne identificerer to datapunkter som outliers, og
data, I skal betragte, indeholder ikke disse.
Data findes i filen tICdata.csv, som har 5 søjler i
rækkefølgen MW, logP, HBA, KA1 og tIC50.
Der er kun 48 datarækker i filen, idet jeg har taget to sæt ud,
som I skal bruge til sidst i opgaven til prædiktion.
- Indlæs data som en datatabel. Opskriv den fulde regressionsmodel, hvor middelværdien af tIC50 afhænger lineært af de fire forklarende variable.
- Lav et qqplot af residualerne i denne model. Angiv Resultat nummer for hvordan et qqplot vurderes
- Reducer den fulde multiple regressionsmodel ved successivt at fjerne led i modellen (backward selektion). Lav en tabel, som for hvert trin angiver den variabel der fjernes i modellen og den tilhørende -værdi.
- Opskriv slutmodellen ved backward selektionsproceduren, og lav et -test for reduktion fra den fulde model til slutmodellen.
- Lav en figur, hvor residualerne fra slutmodellen afsættes mod KA1, og med nullinjen indsat. (Overvej også, hvilke andre figurer du burde lave.) Idet du starter fra venstre side og går mod højre, hvor mange punkter ligger under nullinjen inden det første punkt, der ligger over nullinjen ?
- Lav en figur, hvor tIC50 afsættes mod de forventede værdier, og indsæt identitetslinjen i denne figur. Synes du, at slutmodellen vil være god til at prædiktere tIC50 ?
- Angiv 95%-konfidensintervaller for de to regressionsparametre i din slutmodel. Hvilke kemiske forbindelser skal man lede efter, hvis man gerne vil have en forbindelse, der er god til at bremse BTK ?
- Datasætet indeholder to observationer, der ikke er medtaget i data, som I benyttede ovenfor. Data for de to observationer er Lav et 95%-prædiktionsinterval for tIC50 for hver af de to prøver ovenfor. Ligger den observerede værdi i prædiktionsintervallet ?Som nævnt i indledningen til denne opgave, blev to prøver fjernet fra datasættet, idet disse blev betragtet som outliers. Data for disse to er Gentag ovenstående beregning af prædiktionsinterval for disse to prøver.
I denne øvelse skal I se på NIR-spektre
af småkagedej for at vurdere, om
disse kan bruges til at prædiktere indholdet af vand i dejen.
Data er hentet fra
ppls
pakken i R (programpakke til statistikberegninger),
og er analyseret i de to artikler
Application of near-infrared reflectance spectroscopy to compositional analysis of biscuits and biscuit dough,
og
Bayesian Wavelet Regression on Curves with Applications to a Spectroscopic Calibration Problem.

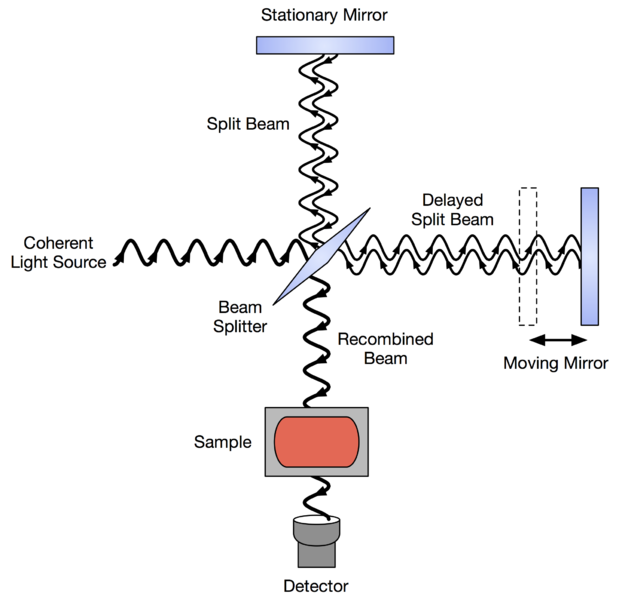 Der er 40 prøver med NIR-spektre målt ved 700 bølgelængder (fra 1100 til 2498
nanometer). Data ligger i filen DejTraen.txt, som
har 701 søjler (uden søjleoverskrifter), hvor den sidste søjle
indeholder mængden af vand. Hver række i filen svarer til en prøve.
Der er 40 prøver med NIR-spektre målt ved 700 bølgelængder (fra 1100 til 2498
nanometer). Data ligger i filen DejTraen.txt, som
har 701 søjler (uden søjleoverskrifter), hvor den sidste søjle
indeholder mængden af vand. Hver række i filen svarer til en prøve.
- Indlæs data som en matriks Traen med brug af indlæsningskommandoen np.loadtxt. Placer NIR-spektrene i en matrix og mængden af vand i vektoren vand (python: T=Traen[:,0:700]). Angiv, hvor mange dejprøver der er med et vandindhold under 13.
- Tabellen nedenfor viser resultatet af et kald til forward samt et kald til cvForward. Illustrer forward selektionsprocessen med en figur som i afsnit 9.4 baseret på data i tabellen ovenfor. Hvor mange variable, fundet ved forward selektion, vil du medtage i en model til beskrivelse af vandindholdet ?
- Du skal nu bruge ridge regression til at beskrive vandmængden ud fra NIR-spektrene. Lav en tabel med krydsvalideringsspredning for -værdierne . Lav også en figur, hvor afsættes mod . Vælg en værdi af , som du vil bruge til at beskrive data med. Lav en figur med den observerede vandmængde afsat mod den forventede vandmængde, og indsæt identitetslinjen i denne figur. Du kan eventuelt lade dig inspirere af koden i den skjulte kode Ridge regression i python.
- Hvilken model foretrækker du, modellen fra forward selektion eller modellen fra ridge regression ?
Opgave 7.3: Prædiktion i ridge regression
Denne opgave er en fortsættelse af den foregående opgave.
Udover det oprindelige datsæt med 40 dejprøver er der også et
nyt datasæt med 32 prøver. Vi kan bruge dette datasæt til
et uafhængigt tjek af, hvor god modellen er til at prædiktere.
Det nye datasæt er i filen DejTest.txt, som
har samme struktur som DejTraen.txt (men altså 32 rækker i
stedet for 40 rækker).
- Indlæs som i foregående opgave data fra filen DejTraen.txt og dan en matriks med spektrene og en vektor vand med indholdet af vand for de 40 prøver. Indlæs dernæst data fra filen DejTest.txt og dan en matrik Ttest med spektrene og en vektor vandtest med indholdet af vand for de 32 nye prøver.
- Betragt først forward selektionsmodellen fra foregående opgave, hvor der medtages 4 variable. Estimer modellen baseret på og vand, og lav prædikterede værdier for prøverne med spektre i Ttest. Dette kan gennemføres under brug af koden i det skjulte punkt Bruge slutmodellen til prædiktion. Udregn testspredningen som kvadratroden af den gennemsnitlige værdi af den kvadrerede afstand mellem prædiktion og den sande værdi, det vil sige Overrasker værdien dig ?
- Betragt nu ridge regression, hvor regulariseringsparameteren vælges til Benyt funktionen ridge til at finde og funktionen cvRidge til at finde prædiktionsspredningen baseret på spektrene i og respons i vand. Angiv den første koordinat i vektoren
- Udregn de prædikterede værdier for de nye data med spektre i Ttest (se koden i det skjulte punkt Ridge prædiktion i python)Lav en figur hvor de observerede værdier for de nye data afsættes mod de prædikterede værdier. Indsæt identitetslinjen i figuren. Hvad er den største abolutte prædiktionsfejl, og hvor optræder den ?
- Udregn testspredningen som kvadratroden af den gennemsnitlige værdi af den kvadrerede afstand mellem prædiktion og den sande værdi. Sammenlign denne værdi med cross-validation prædiktionsspredningen Synes du ridge regressionsmodellen er god til at prædiktere nye dejprøver ?
Opgave 7.4: Teste regressionsmodellen
I opgave 5.8 så I på en regressionsmodel for
absorbansratioens afhængighed af proteinmængden BSA, og brugte
sammenhængen som en kalibreringskurve.
I opgaven var der givet en enkelt observation af absorbansratioen
for hver af seks værdier af BSA. I artiklen
Linearization of the Bradford Protein Assay,
som data stammer fra, er hver absorbansratio faktisk gennemsnit af
tre uafhængige målinger. Alle data fra artiklen er gengivet i tabel
nedenfor og findes i filen TreGentagBradford.csv.
Filen har tre søjler, hvor første søjle indeholder BSA,
den anden søjle er en variabel gruppe, der
koder for BSA-gruppe (med værdierne G1,G2,G3,G4,G5,G6), og
den tredje søjle indeholder absorbansratio.
Et relevant spørgsmål for data af denne type er, om man skal tage gennemsnit
for hver bølgelændge af de tre målinger, før man beregner forhold,
eller om man skal lave forholdet for hver brønd og tage gennemsnit af
disse. Formodentligt giver det en meget lille forskel, men
da respons er lineær for forholdet, vil det være bedst
at betragte forholdet for hver brønd og så
tage gennemsnit. Et andet spørgsmål I skal overveje nedenfor er, om man skal basere
kalibreringskurven på gennemsnit af de tre forhold for hver
proteinmængde, eller om man skal basere beregningerne på alle
18 datapunkter.
- Opstil normalfordelingsmodellen, hvor hver BSA-gruppe har sin egen middelværdi af absorbansratio, og alle grupperne har den samme varians. Analyser modellen i python, og angiv skøn over spredningen i modellen.
- Opstil regressionsmodellen, hvor middelværdien af absorbansratio afhænger lineært af BSA. Analyser modellen i python, og angiv skøn over spredningen i modellen. Hvis man kun betragter data bestående af 6 proteinmængder og 6 absorbansratioer, som hver er gennemsnit af tre målinger, vil en regressionsmodel give et skøn over spredningen på 0.02665. Kan du forstå dette i sammenligning med det skøn, du fik ovenfor (svaret kan godt være "nej") ?
- Forklar, at regressionsmodellen er en undermodel af modellen, hvor hver BSA-gruppe har sin egen middelværdi af absorbansratio (den ensidede variansanalysemodel). Lav et test for reduktion fra den ensidede variansanalysemodel til regressionsmodellen. Angiv den -fordeling, der bruges. Er -værdien stor nok, til at du vil acceptere regressionsmodellen ?
- Beregn et 95%-konfidensinterval for hældningen i den lineære sammenhæng mellem middelværdien af Absorbansratio og BSA. Hvis man igen betragter regressionsmodellen baseret på de 6 gennemsnit, bliver konfidensintervallet Sammenlign dette med det konfidensinterval du lige har fundet.
- Betragt en ny prøve med ukendt indhold af proteinmængden BSA, hvor absorbansratio er målt tre gange med værdierne 0.979, 0.977, 0.984. Angiv et 95%-konfidensinterval for det ukendte indhold af BSA. Hvis man igen betragter regressionsmodellen baseret på de 6 gennemsnit, og en ny måling som er 0.980 (gennemsnittet af de tre målinger ovenfor), bliver konfidensintervallet Ved fremtidig brug af kalibreringskurven til bestemmelse af proteinindholdet vil du da vælge at bruge kurven og spredningskøn baseret på alle 18 datapunkter, eller vil du bruge kurven og spredningsskøn baseret på de 6 gennemsnit ?
Opgave 7.5: Opgave med repetitionselementer
I denne sidste opgave er det meningen, at I
hovedsageligt skal bruge metoderne fra de 6 første øvelser
(undtagelsen er det sidste spørgsmål). I artiklen
Use of Multiple Linear Regression Models for Setting Water Quality Criteria for Copper: A Complementary Approach to the Biotic Ligand Model
betragtes forskellige modeller til at beskrive giftigheden af
kobber i vandløb. Giftigheden, under givne forhold, findes ved at lave en
række forsøg med forskellige koncentrationer af kobber i det vand
hvor vandlopper
(Daphnia magna)
opholder sig i et givet tidsrum. Som beskrivelse af giftigheden bruges
den koncentration af kobber under
hvilken 50 procent af vandlopperne dør. Denne kaldes
acute EC50
(Half maximal effective concentration).
Som modeller for EC50-koncentrationen har man på
den ene side en simplificeret
model, hvor man kun bruger vandets hårdhed som forklarende
variabel i en regressionsmodel. På den anden side har man
en kompliceret multipel regressionsmodel med 10 forklarende
variable, som ifølge forfatterne ikke har vundet indpas i
vandkvalitetsprogrammer. Forfatterne betragter i stedet
en mere simpel multipel regressionsmodel med tre forklarende
variable, henholdsvis DOC (dissolved organic carbon, mg/L),
hårdhed (mg/L)
og pH. I opgaven her skal I betragte data for EC50-koncentrationen af kobber
(g/L Cu). Den bedste skala
at betragte data på er ved at logaritmetransformere værdierne
(dog ikke pH, som allerede er på en log-skala).
Filen Dmagna.csv indeholder variablene
DOC, hardness, pH og
EC50. Der er data for 302 målinger.
 Lad logEC50 være logaritmen til acute EC50, og for
nemhed i notationen lad være logaritmen til DOC og
være logaritmen til hardness. En analyse af den multiple
regression af logEC50 på , og pH viser, at modellen
kan reduceres til
Du kan eventuelt køre en multipel regressionsanalyse og se, at
parametertabellen ikke strider mod
og
Denne analyse giver anledning til at indføre et indeks,
her kaldet giftIndex, på formen
Fra data ses, at dette indeks svinger omkring værdien
Opgaven her går ud på at lave nogle (lidt usædvanlige) undersøgelser
for at se, om den multiple regressionsmodel kan forbedres ved at
inkludere flere variable. Specifikt skal I
se, om produktet indeholder information om
giftindex ved at dele data op i grupper efter denne variabel.
Lad logEC50 være logaritmen til acute EC50, og for
nemhed i notationen lad være logaritmen til DOC og
være logaritmen til hardness. En analyse af den multiple
regression af logEC50 på , og pH viser, at modellen
kan reduceres til
Du kan eventuelt køre en multipel regressionsanalyse og se, at
parametertabellen ikke strider mod
og
Denne analyse giver anledning til at indføre et indeks,
her kaldet giftIndex, på formen
Fra data ses, at dette indeks svinger omkring værdien
Opgaven her går ud på at lave nogle (lidt usædvanlige) undersøgelser
for at se, om den multiple regressionsmodel kan forbedres ved at
inkludere flere variable. Specifikt skal I
se, om produktet indeholder information om
giftindex ved at dele data op i grupper efter denne variabel.
- Indlæs data og dan variablene logEC50, , og pH. Dan dernæst giftIndex. Tjek at gennemsnit af målingerne af giftIndeks er
- Konstruer en kategorisk variabel gruppe, der deler op i tre grupper, , og , efter om er mindre end 25, er mellem 25 og 35 eller over 35. I python (pandas) kan dette gøres med kommandoen Dan nu to datasæt, giftA og giftC, med værdierne af giftIndex hørende til gruppe og til gruppe . Der er 60 observationer i gruppe og 96 i gruppe .
- For de 60 prøver i gruppe er der 14, der har en værdi af giftIndex under (konstater, at dette er rigtigt). Opstil en statistisk model til beskrivelse af observationen 14, og lav et 95%-konfidensinterval for sandsynligheden for, at værdien af giftIndex er under i gruppe .
- For de 96 prøver i gruppe er der 29, der har en værdi af giftIndex under Undersøg, om der er samme frekvens af prøver med en værdi af giftIndex under i de to grupper og .
- Opstil en statistisk model til beskrivelse af værdierne af giftIndex i giftA og giftC. Lav et test for hypotesen, at der er samme middelværdi af giftIndex i de to grupper og .
- Betragt nu giftIndex for alle 3 grupper dannet ud fra faktoren gruppe. Opstil en statistisk model for data, og undersøg først, om der er samme varians for de tre grupper, og dernæst, om der er samme middelværdi for de tre grupper.
- Ovenstående analyse viser, at der er information i produktet , der kan bruges til at beskrive giftIndex, og dermed kan bruges til at beskrive logEC50. I dette delspørgsmål skal I analysere en multipel regressionsmodel til beskrivelse af logEC50, hvor I som forklarende variable ud over , og pH også bruger alle produkter af disse, det vil sige, variablene Opskriv den multiple regressionsmodel, hvor alle 9 forklarende variable inddrages.Reducer modellen ved brug af backward selektion.
- Lav et test for reduktion fra startmodel til slutmodellen fremkommet ved backward selektion.Angiv et 95%-konfidensinterval for regressionskoefficienten hørende til variablen i slutmodellen.I din slutmodel, hvor meget stiger middelværdien af logEC50 hvis dissolved organic carbon stiger fra 2 til 10 ?
- Overvej, hvilke figurer du ville lave til kontrol af slutmodellen (du skal ikke lave figurerne).
- Sammenlign endelig skøn over spredning i slutmodellen med skøn over spredning i den multiple regressionsmodel hvor kun de tre forklarende variable , og pH inddrages. Er det rimeligt at bruge denne sidste simple model ?
Opgave 7.6: Bruge ophobningsloven
Betragt data fra opgave 7.1 og den multiple regressionsmodel for
tIC50 med de to forklarende variable logP
og KA1. Analyse af denne model giver
ForegåendeNæste
- Lav et approksimativt 95%-konfidensinterval for parameteren