Afsnit 4.3: Teste middelværdier ens når varianser er forskellige
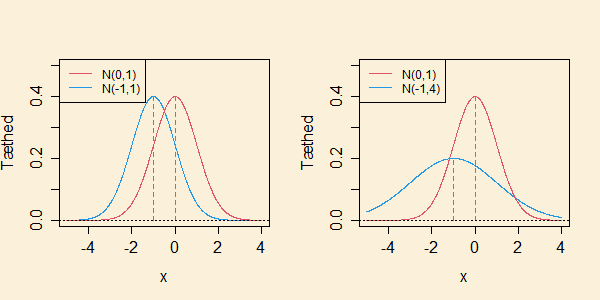
Resultat 4.3.1.
(Welch's -test)
Til at teste hypotesen om ens middelværdier, mod
alternativet i
Statistisk Model 4.1.1,
hvor hver gruppe har sin egen varians, benyttes teststørrelsen
fra (4.3.1) med tilhørende
observeret værdi og en approksimativ
-værdi beregnes som
Endvidere er et 95%-konfidensinterval for forskel
i middelværdi mellem gruppe 1 og gruppe2,
det vil sige for parameteren
givet ved formlen
Man kan vise, at altid er større end eller lig med
det mindste af de to frihedsgradsantal og
og mindre end eller lig med
Metoden givet ovenfor kaldes Welch's -test. Spørgmålet, om der findes et eksakt test for hypotesen
kendes under navnet
Behrens–Fisher problem.
Eksempel 4.3.2.
(Opdagelsen af Argon)
Lord Rayleigh lavede i 1890-erne en række målingerne af massefylden af
kvælstof og opdagede en forskel i massefylden afhængig af måden
det formodede rene kvælstof blev udvundet på. Dette førte senere
til opdagelsen af luftarten argon og Lord Rayleigh fik i 1904
Nobelprisen i fysik for denne opdagelse.
 I artiklen
On an Anomaly encountered in Determinations of the Density of Nitrogen Gas
Er der 7 målte værdier fremkommet ved at ilt fjernes fra atmosfærisk luft
og 8 målte værdier ved reaktioner med kemiske forbindelse hvor kvælstof indgår.
Målingen er massen i gram af indholdet i en glaskugle (vistnok med rumfang på
1.836 liter) og er bestemt med stor nøjagtighed. Vi lader være massemålingen for den 'te prøve,
hvor ilt fjernes fra atmosfæren, og lader
være den 'te måling, når der bruges en
kemisk forbindelse.
Vi benytter Statistisk Model 4.1.1, her skrevet som
hvor kan variere frit.
QQplots nedenfor støtter normalfordelingsmodellen, og
både qqplots og boxplots peger i retning af forskellige varianser
i de to observationssæt. Rayleigh brugte eksperimentet til at påvise en forskel i massen af
kvælstof ved de to metoder. Rayleigh brugte ikke statistiske metoder
(de var ikke kendte på daværende tidspunkt), men følte sig sikker i
konklusionen ud fra de målte værdier. Vi vil
formulere problemstillingen som hypotesen, at de to middelværdier er ens
-teststørrelsen for denne hypotese,
når varianserne er forskellige, bliver
baseret på følgende beregnede værdier
Den tilhørende -værdi fra en -fordeling er
Da denne er meget mindre end 0.05, bliver konklusionen, at data strider mod
samme middelværdi, og da
tyder data altså på, at kvælstof udvundet fra atmosfæren har en højere
masse. Forskellen i massen ved de to udvindingsmetoder kan angives
ved et 95%-konfidensinterval for forskellen i middelværdi.
Hertil finder vi 97.5%-fraktilen i en -fordeling,
og konfidensintervallet bliver
Middelværdien af massen af kvælstof fra atmosfæren
ligger med 95% sikkkerhed mellem 0.0095 og 0.0118 gram over
middelværdien for kvælstof fra kemiske forbindelser.
I artiklen
On an Anomaly encountered in Determinations of the Density of Nitrogen Gas
Er der 7 målte værdier fremkommet ved at ilt fjernes fra atmosfærisk luft
og 8 målte værdier ved reaktioner med kemiske forbindelse hvor kvælstof indgår.
Målingen er massen i gram af indholdet i en glaskugle (vistnok med rumfang på
1.836 liter) og er bestemt med stor nøjagtighed. Vi lader være massemålingen for den 'te prøve,
hvor ilt fjernes fra atmosfæren, og lader
være den 'te måling, når der bruges en
kemisk forbindelse.
Vi benytter Statistisk Model 4.1.1, her skrevet som
hvor kan variere frit.
QQplots nedenfor støtter normalfordelingsmodellen, og
både qqplots og boxplots peger i retning af forskellige varianser
i de to observationssæt. Rayleigh brugte eksperimentet til at påvise en forskel i massen af
kvælstof ved de to metoder. Rayleigh brugte ikke statistiske metoder
(de var ikke kendte på daværende tidspunkt), men følte sig sikker i
konklusionen ud fra de målte værdier. Vi vil
formulere problemstillingen som hypotesen, at de to middelværdier er ens
-teststørrelsen for denne hypotese,
når varianserne er forskellige, bliver
baseret på følgende beregnede værdier
Den tilhørende -værdi fra en -fordeling er
Da denne er meget mindre end 0.05, bliver konklusionen, at data strider mod
samme middelværdi, og da
tyder data altså på, at kvælstof udvundet fra atmosfæren har en højere
masse. Forskellen i massen ved de to udvindingsmetoder kan angives
ved et 95%-konfidensinterval for forskellen i middelværdi.
Hertil finder vi 97.5%-fraktilen i en -fordeling,
og konfidensintervallet bliver
Middelværdien af massen af kvælstof fra atmosfæren
ligger med 95% sikkkerhed mellem 0.0095 og 0.0118 gram over
middelværdien for kvælstof fra kemiske forbindelser.
ForegåendeNæste
Nedenstående kodevindue laver qqplots og boxplots af de to datasæt, og laver
de beregnede værdier benyttet ovenfor.
I afsnit 4.5 laves testet for ens middelværdier
mere simpelt under brug af mere avancerede pythonfunktioner.
Kommenter, ud fra den dannede figur, på forholdet mellem de to varianser og
forholdet mellem de to middelværdier.
Der ser ud til at være forskellig hældning i de to qqplots, hvilket tyder
på forskellig varians i de to grupper af observationer. Den samme tendens
ses i boxplottene: det højre boxplot har større udstrækning.
Boxplottene indikerer også, at der er forskel i middelværdi i de
to grupper: kassen i det venstre boxplot ligger højere end kassen i det
venstre boxplot.