Afsnit 3.2: Normal-qqplot
Eksempel 3.2.1.
(Jordens massetæthed)
Henry Cavendish
lavede i 1797 et eksperiment til bestemmelse af Jordens massetæthed.
Eksperimentet går ud på at bestemme den
universelle gravitationskonstant i Newtons lov, som siger, at
tiltrækningskraften mellem to legemer er . Her er og
masserne af de to legemer og er afstanden mellem dem.
Når vi ser på kraften hvormed jorden trækker i et legeme
med masse kan vi skrive denne både som , hvor er
tyngdeaccelerationen og som hvor er
Jordens masse og er Jordens radius. Hvis vi lader være
Jordens massetæthed, har vi og kan derfor udlede, at
, således at bestemmelse af giver en
bestemmelse af Cavendish's eksperiment til bestemmelse af er
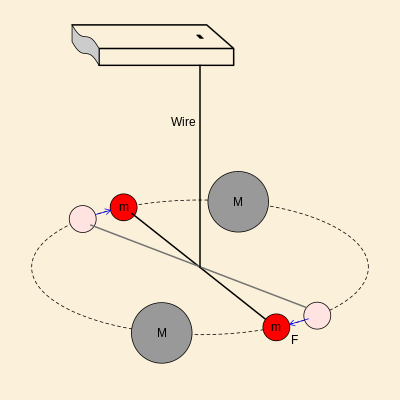
illustreret i følgende figur, hvor tiltrækningskraften mellem to
kugler bestemmes ud stivheden i en wire der holder den ene kugle.
Cavendish's eksperiment er lavet med to forskellige wires og I
afsnit 3.5 betragter jeg de
23 målinger hørende til den ene wire.
Jeg vil undersøge om Cavendish er nået frem til den samme massetæthed for
Jorden som i moderne eksperimenter, det vil sige værdien 5.517
relativt til tætheden for vand (enhed brugt af Cavendish).
Jeg er også interesseret i variationen i data som udtryk for
kvaliteten af Cavendish's eksperiment.
Jeg vil gerne bruge normalfordelingen til at beskrive mine data, men
er dette rimeligt ? Jeg har ikke nok data til at lave et
goodness of fit test som beskrevet i afsnit
2.4, og som I prøvede at lave i
Opgave 3 i Øvelse 2. I stedet vil jeg her beskrive
en grafisk undersøgelse, der kan give en indikation af, om det er rimeligt
at bruge en normalfordeling. I den grafiske metode laves en figur, hvor
punkterne bør "sno sig" omkring en ret linje, i fald data stammer fra
en normalfordeling. Med kun ganske få datapunkter, som i mit eksempel
ovenfor, kan det være svært at afgøre, om data afviger fra at "sno sig"
omkring en ret linje. Den grafiske undersøgelse er således af større
værdi, hvor man har flere datasæt og kan se, om de alle viser den samme
form for afvigelse fra "sno sig" egenskaben. Resultat 3.2.2.
(Brugen af normal-qqplot)
I Python konstrueres et (normal-) qqplot med kommandoen
qqplot. Punkterne der tegnes vil altid være stigende (
for to på hinanden følgende punkter), og som
beskrevet til sidst i dette afsnit, forventer vi, at hvis data stammer fra en
normalfordeling, så vil punkterne sno sig omkring en ret linje.
Det følgende kodevindue laver den grafiske undersøgelse for data i
eksemplet ovenfor.
I Python hedder den relevante funktion qqplot.
For at figuren bliver som beskrevet nedenfor, skal man altid tilføje
a=0.5 i kaldet.
Man kan få en linje indsat, der går gennem første og tredje
kvartil af data
ved at tilføje line='q' i kaldet til qqplot
(Python bruger en algoritme til beregning af kvartiler, der ikke er
optimal, når antallet af observationer er lille).
Figuren, der dannes i kodevinduet her, understøtter, at Cavendish's
målinger kan beskrives med en normalfordeling. Prøv at finde
værdien 5.517 på andenaksen i figuren, og vurder om denne ligger
centralt blandt målingerne.
Jeg beskriver nu den grafiske undersøgelse,
lavet i kodevinduet ovenfor, som går under navnet
normal-qqplot. Her står "q" for quantile, som på dansk
er fraktil, og på dansk taler man om en fraktilsammenligning.
For nemhed i notationen vil jeg fremover blot omtale metoden som et
qqplot. For at beskrive metoden lader jeg være
-fraktilen i en standard normalfordeling, -fordelingen,
det vil sige, at
I Python beregnes -fraktilen som st.norm.ppf(p). Vi betragter datapunkter
og ordner disse efter størrelse,
betegner den mindste, den næstmindste, og så videre op til
som er den største:
Et qqplot består i at tegne punkterne
I Python produceres denne figur, når der i kaldet til qqplot
tilføjes
I nedenstående kodevinduer vises nogle eksempler på qqplots.
Først kommer et kodevindue, hvor data er normalfordelt.
Der laves en figur med fire qqplots, alle med det samme antal
observationer. Prøv at køre koden et par gange. Prøv dernæst at
ændre fra 10 til 40, og dernæst til 100. Kommandoen
norm.rvs(0,1,n)
simulerer observationer fra en standard
normalfordeling.
Nu følger et kodevindue, der danner en figur med fire
qqplots, og hvor data ikke er normalfordelte for de sidste to
qqplots.
Prøv at køre koden et par gange. Prøv dernæst at
ændre fra 10 til 40, og dernæst til 100.
Hvorfor giver et qqplot en figur,
hvor normalfordelte data snor sig omkring en ret linje ?
Her er kort den tekniske ide bag et qqplot.
Hvis data følger en -fordeling,
så bør der gælde, at for ethvert mellem 0 og 1 vil fraktilen
beregnet ud fra data ligne -fraktilen i en
fordeling. Hvis
kan vi skrive hvor hvorfor
-fraktilen for kan skrives som Hvad mener
jeg med fraktiler beregnet ud fra data ?
Per definition af de ordnede værdier vides,
at i punktet er andelen af data mindre end eller
lig med denne værdi givet ved men hvis vi betragter en værdi
lidt mindre end (men større end ), er
andelen af data mindre end eller
lig med denne værdi i stedet Vi vælger derfor at sige, at
er et skøn over -fraktilen. Vores argument
er derfor, at hvis data er fordelt, så bør
hvor "" skal læses som "cirka lig med".
I qqplottet bør punkterne derfor sno sig om en linje med hældning
- I det øvre højre delplot betragtes data fra en normalfordeling. Hvad er middelværdi og spredning i denne normalfordeling ?
- I det nedre venstre delplot betragtes data fra en stokastisk variabel, der kun kan antage positive værdier. Hvad er fordelingen af logaritmen til den stokastiske variabel ?
- Der simuleres først data data fra en fordeling, hvorefter disse ganges med 2 og der lægges 3 til. Dette betyder, at de nye data stammer fra en -fordeling, middelværdi er 3 og spredning er 2.
- Data kommer fra en stokastisk variabel hvor er -fordelt. Hvis vi tager logaritmen, får vi som er normalfordelt. Man siger, at er log-normalfordelt.
Shapiro-Wilks test som supplement
Et QQplot giver et godt visuelt indblik i data. Hvis antallet af observationer
er lille, kan det dog være svært at vurdere, om data kan siges at
følge en normalfordeling.
Mange statistikpakker indeholder muligheden for at lave et mere formelt test.
En af de populære metoder er
Shapiro-Wilks test.
Jeg vil ikke gå ind på en
nærmere beskrivelse her, men blot nævne at testet kan udføres med kommandoen
st.shapiro(x), hvor er en vector med data. Dette vises i kodevinduet
nedenfor med målingerne af jordens massetæthed foretaget af Cavendish.
ForegåendeNæste