Afsnit 6.10: Analyse af korrosionshæmmere
6.10.1 Bartletts test i gruppespecifik regression
Da vi kan antage, at de tre varianser er ens, betragtes nu den gruppespecifikke regressionsmodel 6.9.2, her skrevet som Det venstre delplot i figuren nedenfor viser data med de tre estimerede linjer indtegnet, og vi ser, at de tre linjer næsten er parallelle. Hvis vi laver -testet for reduktion fra den gruppespecifikke regressionsmodel til den gruppespecifikke skæringsmodel (6.9.1), hvor de tre grupper af observationer har den samme hældning i den lineære sammenhæng, får vi en -værdi på 0.77. Data strider altså ikke mod hypotesen I figuren nedenfor viser det midterste plot de estimerede linjer med samme hældning, og det højre delplot er et normalt qqplot af residualerne i den estimerede model. Skøn og konfidensintervaller for parametrene i modellen med samme hældning er, Et test, i den gruppespecifikke skæringsmodel, for hypotesen om samme skæring, giver en -værdi på 0.0020 (se koden nedenfor for de forskellige kald af anovalm). Modellen kan altså ikke reduceres til den simple lineære regressionsmodel, hvor alle tre hæmmere har den samme lineære sammenhæng. I modellen med fælles hældning ligger INH2-hæmmeren cirka 2.3 over INH1, og INH3 ligger yderligere cirka 2.3 over INH2. Forfatterne til artiklen, hvor data stammer fra, skriver i konklusionen: "INHs act as effective corrosion inhibitors and their efficiencies increase with increased concentration" og forfatterne lægger som sådan ikke vægt på forskellen mellem de tre hæmmere.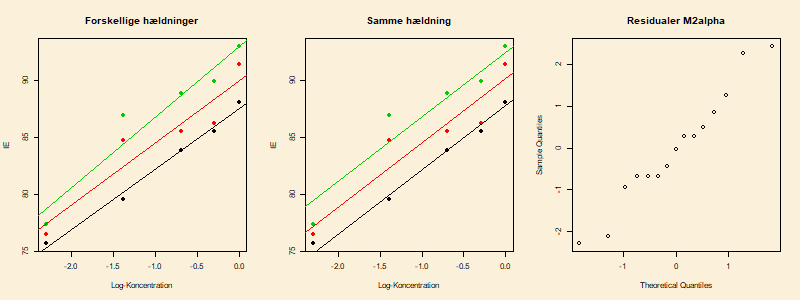
6.10.2 F-tests og parametertabel
ForegåendeNæste