Afsnit 6.8: Øvelse 4
Opgave 4.1: Two-sample $t$-test, samme varians
Visse microorganismer producerer biofilm på forskellige overflader,
hvilket for eksempel kan vanskeliggøre en sygdomsbekæmpelse.
I artiklen
Epigallocatechin gallate remodels overexpressed functional amyloids in Pseudomonas aeruginosa and increases biofilm susceptibility to antibiotic treatment
studeres muligheden for at bekæmpe biofilm
ved hjælp af Epigallocatechin 3-gallates (EGCG, stof der
forekommer i grøn te).
Artiklen har 12 forfattere, hvoraf 4 har tilknytning til iNANO
på Aarhus Universitet.
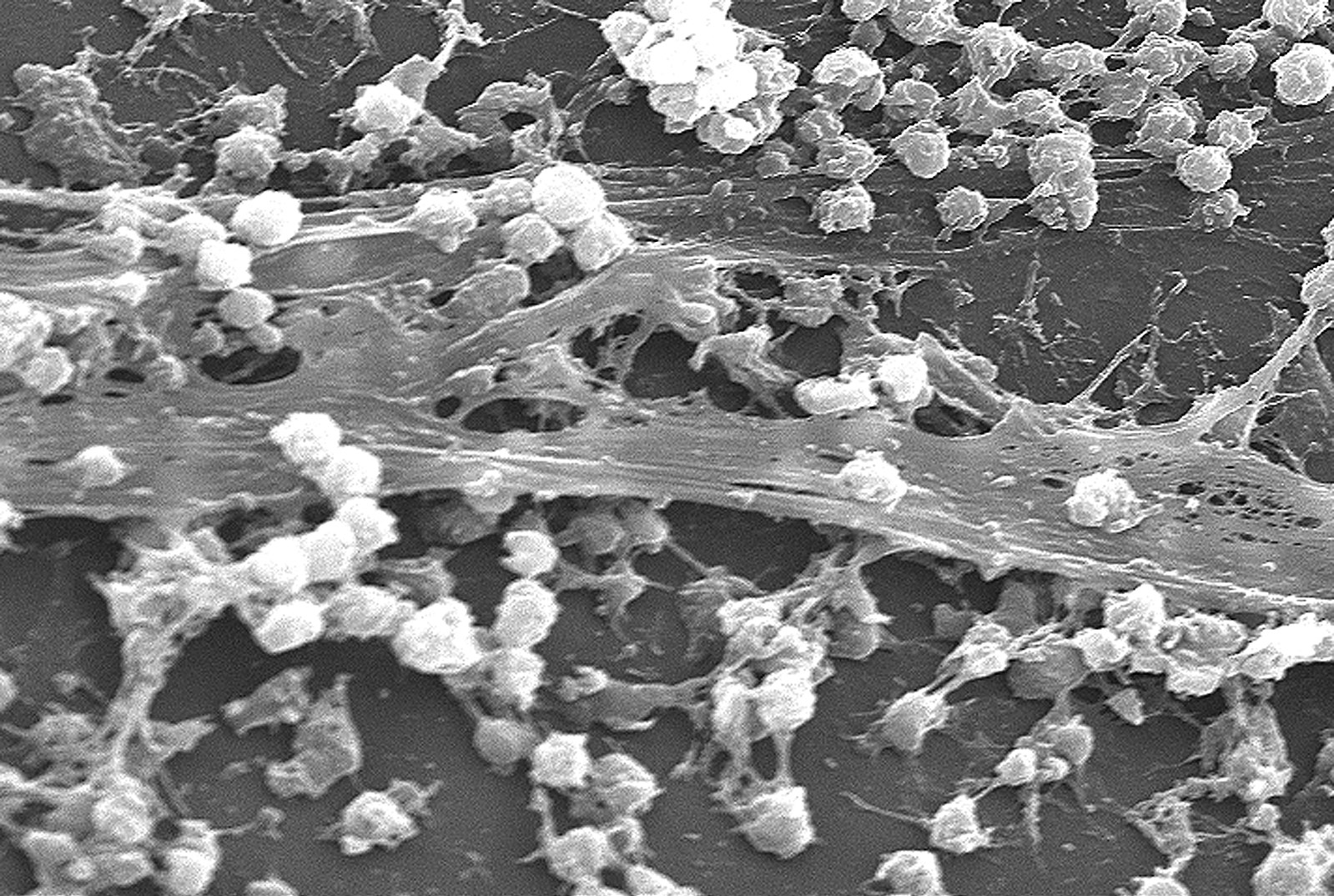
 I denne opgave skal I se på biofilmens stivhed (Youngs modulus målt i kPa).
Der er lavet 4 eksperimenter i alt med to forskellige bakterier, og hvor
der enten tilsættes EGCG eller ikke tilsættes EGCG. De oprindelige rådata
er ikke tilstede, men fra artiklen kan man fra figur aflæse gennemsnit
og empirisk spredning baseret på 10 observationer
(at der er 10 observationer i hvert eksperiment fremgår af sidste
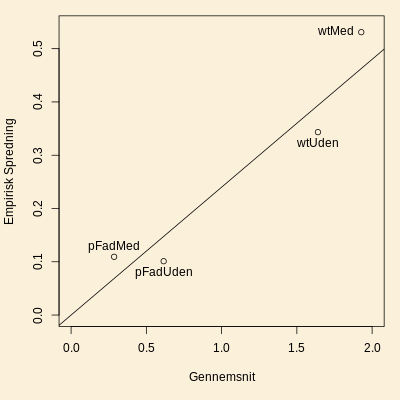
afsnit i artiklen). Højre del af ovenstående figur viser
empirisk spredning afsat
mod gennemsnit. Figuren peger på proportionalitet mellem
spredning og middelværdi. I sådanne situationer fører en log-transformation
af data typisk til varianshomogenitet mellem grupperne.
I skal I denne opgave betragte pFad bakterien med og uden tilsætning
af EGCG.
Data findes i filen BiofilmPFad.csv, der har to søjler,
hvor den første søjle angiver, om der er tilsat EGCG
(angivet som med og uden), og den anden
søjle indeholder biofilmens stivhed.
I denne opgave skal I se på biofilmens stivhed (Youngs modulus målt i kPa).
Der er lavet 4 eksperimenter i alt med to forskellige bakterier, og hvor
der enten tilsættes EGCG eller ikke tilsættes EGCG. De oprindelige rådata
er ikke tilstede, men fra artiklen kan man fra figur aflæse gennemsnit
og empirisk spredning baseret på 10 observationer
(at der er 10 observationer i hvert eksperiment fremgår af sidste
afsnit i artiklen). Højre del af ovenstående figur viser
empirisk spredning afsat
mod gennemsnit. Figuren peger på proportionalitet mellem
spredning og middelværdi. I sådanne situationer fører en log-transformation
af data typisk til varianshomogenitet mellem grupperne.
I skal I denne opgave betragte pFad bakterien med og uden tilsætning
af EGCG.
Data findes i filen BiofilmPFad.csv, der har to søjler,
hvor den første søjle angiver, om der er tilsat EGCG
(angivet som med og uden), og den anden
søjle indeholder biofilmens stivhed.
- Indlæs data og dan vektorerne behandling og stivhed ud fra søjlerne i de indlæste data. Dan dernæst to datasæt, med og uden, med logaritmen til værdierne fra stivhed delt op efter behandling, for eksempel kan det første datasæt dannes med kommandoen (se afsnit 6.6 for et eksempel på udtræk af data fra datatabel). Tjek, at der er 10 observationer i hvert af de to datasæt (antallet af elementer i en vektor kan i python findes med funktionen len).
- Lav en figur med et qqplot for hvert af de to datasæt. Koden, til at lave flere qqplots i den samme figur, kan du se i kodevinduet i starten af kapitel 6. Synes du, at logaritmen til biofilmens stivhed for hver behandling kan beskrives med en normalfordeling ?Lav også en figur med boxplot for hvert af de to datasæt. Flere boxplots i den samme figur kan laves som vist i kodevinduet i starten af kapitel 6. Hvilke ligheder og forskelle mellem de to datasæt kan du se i denne figur ?
- Opstil modellen, hvor logaritmen til stivheden for hver gruppe (med og uden) følger sin egen normalfordeling (husk at angive Statistisk Model nummer). Udregn gennemsnit og empirisk spredning for hvert af de to datasæt. Angiv et 95%-konfidensinterval for middelværdien for hvert af de to datasæt.
- I skal nu antage at der er samme varians i de to datasæt. Opstil modellen, hvor logaritmen til stivheden er normalfordelt, og de to datasæt har hver sin middelværdi, men samme varians. Opstil hypotesen at de to middelværdier er ens, og lav et test af denne hypotese. Er det rimeligt at antage, at biofilmens stivhed har samme middelværdi for de to behandlinger ?
- Angiv et 95%-konfidensinterval for forskellen i middelværdi af logaritmen til biofilmens stivhed mellem gruppen med tilsætning af EGCG og gruppen uden tilsætning. Synes du, at forskellen mellem de to middelværdier i denne opgave er stor (se begrebet effektstørrelse i eksempel 6.2.2) ?
- Konfidensintervallet i foregående spørgsmål er for forskellen mellem middelværdierne for logaritmen til hårdheden. Oversæt konfidensintervallet til et 95%-konfidensinterval for forholdet mellem middelværdierne af hårdheden.
- Ovenfor antog I, at der er samme varians i de to grupper på logaritmen til hårdheden. Opskriv hypotesen, at de to varianser er ens, og lav et test for denne hypotese. Resultatet af dette test kan måske gøre jer lidt bekymrede i forhold til antagelsen om samme varians, men opgave 4.6 nedenfor skulle gerne fjerne jeres bekymring igen.
Opgave 4.2: Two-sample $t$-test, forskellig varians
I renseanlæg kan det være et problem, hvis der dannes skum på
overfladen af spildevandet. Det er derfor af interesse at
kunne måle spildevandets evne til at danne skum. I artiklen
Evaluating the Measurement of Activated Sludge Foam Potential
sammenlignes to metoder til dette. Ved den ene metode (Luft)
blæses der luftbobler gennem spildevandet, og ved
den anden metode (AS: Alka-Seltzer tabletter) tilsættes en tablet til spildevandet
overflade, der bevirker en kemisk reaktion. Ved hver af de to
metoder er eksperimentet gentaget 20 gange, og hver gang måles
højden på det dannede skum. For data i opgaven her er
højden omregnet til en procentdel i forhold til mængden af
spildevand. Data er simulerede i overensstemmelse med
oplysningerne i artiklen og findes i filen Skum.csv, der har
søjlerne Metode og Hoejde.
Da de to metoder er meget forskellige, forventer vi ikke, at
variansen på højden af skummet er den samme ved de to metoder.
- Indlæs data fra filen Skum.csv. Lav to datasæt med højden af skummet svarende til de to metoder til at frembringe skummet. Hvad er den største værdi blandt Luft-målingerne ?
- Lav en fælles figur med qqplots for begge datasæt. Synes du, at højden af skummet for hver metode kan beskrives med en normalfordeling ?Lav en figur, der indeholder boxplot af skumhøjden for de to metoder. Hvilke ligheder og forskelle mellem de to datasæt kan du se i denne figur ?
- Opstil modellen, hvor hvert datasæt følger sin egen normalfordeling.
- Angiv et 95%-konfidensinterval for forskellen i middelværdi af skumhøjden mellem Luft-metoden og AS-metoden. Angiv Resultat fra webbogen, der bruges til at lave konfidensintervallet.Synes du, at forskellen mellem de to middelværdier er stor ?
- Forskellen i middelværdi siger ikke i sig selv, om den ene metode er mere brugbar end den anden. En anden vigtig egenskab er reproducerbarheden i en måling beskrevet via spredningen i fordelingerne. Lav et test for hypotesen, at der er samme spredning i målingerne for de to metoder. Lav også et 95%-konfidensinterval for forholdet mellem de to spredninger. Angiv Resultat fra webbogen, der bruges til at lave testet.Hvilken af de to metoder foretrækker du ?
- Angiv sandsynligheden for at få en værdi over 2.3 i en -fordeling med 27 frihedsgrader.
- Find 97.5%-fraktilen i en -fordeling med 10 frihedsgrader
- Angiv sandsynligheden for at få en værdi under 2.228 i en -fordeling med 10 frihedsgrader.
Opgave 4.4: T-test baseret på opsummerede data
For de -test, der udføres i denne bog, er udgangspunktet, at alle
data er til rådighed. Imidlertid viser formlerne, at de forskellige
test kan udføres, hvis blot gennemsnit og empiriske spredninger, samt
antallet af observationer der ligger bagved, er til rådighed. Et (formodentligt konstrueret) eksempel på dette kan findes i
opgave 4.13 i den syvende udgave af
Quantitative Chemical Analysis. En bioanalytiker under optræning
(trainee)
vil være klar til at arbejde selvstændigt, hvis vedkommende opnår
resultater sammenlignelige med resultater opnået af en erfaren
bioanalytiker. En blodprøve deles op i 11 dele, hvor bioanalytikeren under
optræning måler blood urea nitrogen
på de 6 dele og den erfarne bioanalytiker på de 5
andre dele. Det må i opgavebesvarelsen antages, at målingerne er
normalfordelte.
Opsummerede resultater for de to bioanalytikere
er i den følgende tabel.
Da vi ikke ved, om trainee er kommet op på niveau med
den erfarne bioanalytiker, vil vi ikke
på forhånd antage, at der er samme varians i de to måleserier.
- Udregn forskel i gennemsnit som en procentdel af gennemsnit for den erfarne bioanalytiker. Synes du, at forskellen er stor eller lille ?
- Opstil en statistisk model for data. Lav et test for hypotesen, at der er samme middelværdi i de to måleserier.
- Lav et 95%-konfidensinterval for forskel i middelværdi mellem trainee og erfarne.
- Det er også af interesse at se, om der er en forskel i variansen. Undersøg, om det kan antages, at der er samme varians i målingerne for trainee og erfarne.
- Overvej, om bioanalytikeren under oplæring er klar til at arbejde selvstændigt.
Jeg har simuleret data, således at gennemsnit og empirisk spredning
er som i tabellen ovenfor. Med disse data kan I kontrollere jeres
beregninger ved at bruge kommandoerne fra
Afsnit 6.5.
Opgave 4.5: Ophobningslov for differens
Betragt data i opgave 4.4.
- Benyt ophobningsloven til at lave et approksimativt 95%-konfidensinterval for forskel i middelværdi mellem Trainee og Erfarne bioanalytiker af en måling af "blood urea nitrogen".
- Sammenlign med et 95%-konfidensinterval baseret på -fordelingen.
I denne opgave skal I betragte data omtalt i opgave 4.1
omkring stivhed af biofilm,
hvor vi deler data ind efter bakterietype (pFad eller
wt) og efter behandling (med eller uden tilsætning af
EGCG). Dette giver i alt fire grupper af observationer.
Data findes i filen BiofilmAlle.csv med to søjler.
Første søjle med navnet Gruppe er kombinationen af bakterietype
og behandling med værdierne pFadMed, pFadUden, wtMed og
wtUden, og anden søjle med navnet Stivhed
er biofilmens stivhed.
- Indlæs data fra BiofilmAlle.csv som en datatabel. Konstruer en ny datatabel, indeholdende søjlen Gruppe og en søjle med logaritmen til stivhed (eller tilføj en søjle med logaritmen til stivhed til den indlæste datatabel).
- Opstil modellen, hvor logaritmen til stivheden er normalfordelt med hver sin middelværdi og varians i de fire grupper.
- Opstil hypotesen, at de fire varianser er ens.Lav Bartletts test for hypotesen om ens varianser
- Ovenfor så I, at data ikke strider mod hypotesen om samme varians i de fire grupper. Omvendt lavede I til sidst i opgave 4.1 et test, der tydede på, at to af varianserne er forskellige. Hvordan passer disse to ting sammen ? Sammenhængen består I, at når man har fire variansskøn, vil det ofte være sådan, at man kan vælge to ud af de fire, hvor det ser ud til, at de underliggende varianser er forskellige. Dette illustreres i simulationen nedenfor. Konkret simuleres der 1000 sæt med fire variansskøn, og så laves der et test og tilhørende -værdi, for at to varianser er ens, baseret på den mindste og den største af de fire variansskøn. Til sidst tælles der op, hvor stor en andel af de 1000 simulerede tilfælde der giver en -værdi mindre end 0.05. Kør koden. Hvor ofte bliver -værdien mindre end 0.05 ?
- Hvis du ikke allerede har gjort det, så leg med koden i eksempel 6.7.1.
Opgave 4.7: Jeres egen ophobningslov
Find et eksempel på brugen af ophobningsloven i et af jeres andre
kurser på universitetet, eller eventuelt fra jeres gymnasieundervisning. Hvis I ikke mener at have set ophobningsloven, så find et eksempel på nettet.
Opgave 4.8: Afleveringsopgave 3
I forbindelse med besvarelsen af denne opgave skal du downloade
filen svarAflevering3.txt fra kursushjemmesiden og indsætte nogle tal
fra din besvarelse som angivet nedenfor. Filen skal afleveres
sammen med din pdf-fil med besvarelsen.Når man skal undersøge effekten af en behandling,
kan det være nødvendigt at overveje, om der kan være
en placeboeffekt. Dette betyder, at en deltager i
eksperimentet kan vise et positivt respons, selvom
behandlingen ikke har nogen effekt. For at tage
højde for dette gør man ofte det, at deltagerne i
eksperimentet deles op i to grupper, hvor den ene gruppe
(i opgaven her procyanidin-gruppen) bliver behandlet med det stof, man ønsker
at undersøge, hvorimod den anden gruppe (placebo-gruppen)
bliver behandlet med et virkningsløst stof. I et
dobbeltblindt forsøg ved hverken deltagerne eller behandlerne
hvilken af de to grupper en person tilhører, og dette
afsløres først når behandlingsperioden er afsluttet. I denne opgave skal I se på effekten af
Procyanidin B-2 (et stof i æbler: se figur nedenfor) til fremme af hårvæksten
på mænd med varierende grad af skaldethed. I et
dobbeltblindt eksperiment er der 19 deltagere i gruppen,
der behandles med Procyanidin B-2, og 10 deltagere,
der behandles med et placebostof. Data kan ses
direkte i artiklen
Investigation of topical application of procyanidin B-2 from apple to identify its potential use as a hair growing agent
 I filen Skaldethed.csv er resultaterne vedrørende tilvækst
i antallet af hår i et kvadrat stort område
for alle 29 personer. Filen er organiseret i to søjle, hvor den ene søjle
angiver behandlingen, og den anden søjle angiver tilvæksten i antallet af hår.
(En enkelt måling af antal hår er gennemsnit af, at tre
personer har talt antallet af hår på et billede tre gange hver.)
Det må i besvarelsen af opgaven antages, at tilvæksten i antallet af hår er
normalfordelt. Da de to grupper modtager forskellig behandling,
kan vi ikke på forhånd antage, at varianserne i de to grupper er ens
I filen Skaldethed.csv er resultaterne vedrørende tilvækst
i antallet af hår i et kvadrat stort område
for alle 29 personer. Filen er organiseret i to søjle, hvor den ene søjle
angiver behandlingen, og den anden søjle angiver tilvæksten i antallet af hår.
(En enkelt måling af antal hår er gennemsnit af, at tre
personer har talt antallet af hår på et billede tre gange hver.)
Det må i besvarelsen af opgaven antages, at tilvæksten i antallet af hår er
normalfordelt. Da de to grupper modtager forskellig behandling,
kan vi ikke på forhånd antage, at varianserne i de to grupper er ens
- Indlæs data, og dan to datasæt med tilvæksten i antallet af hår for de to grupper, procyanidin-gruppen og placebo-gruppen. Beregn gennemsnit af målingerne for placebo-gruppen. Overfør den fundne værdi, med tre decimaler, til svarAflevering3.txt. Lav en figur, hvor tilvæksten afsættes langs andenaksen og alle målingerne hørende til procyanidingruppen har førstekoordinat 1 og alle hørende til placebogruppen har førstekoordinaten 2.
- Opstil modellen, hvor hver gruppe har sin egen normalfordeling. Overfør Statistisk Model nummer til svarAflevering3.txt.
- Angiv et 95%-konfidensinterval for forskel i middelværdi mellem behandlingsgruppen og placebogruppen. Angiv hvilken fordeling, der bruges til konstruktionen af konfidensintervallet. Overfør til svarAflevering3.txt Resultat nummer fra webbogen til konstruktion af konfidensintervallet. Overfør den øvre grænse i konfidensintervallet, med 3 decimaler, til filen svarAflevering3.txt.
- Angiv -værdien for et test af hypotesen om samme middelværdi af tilvæksten i de to grupper.
- Undersøg, om data stemmer overens med en hypotese om samme varians i de to grupper. Overfør -værdi med 3 decimaler, til svarAflevering3.txt.
I en RT-PCR analyse af 8 prøver er ekspressionsniveauet blandt andet målt
for de fire gener CFL1, ATP5B, CFL1 og ACTB.
Gennemsnit og empirisk varians for logaritmen til ekspressionsniveauet for
hvert gen er vist i den følgende tabel.
(Data er fra hjemmesiden for
Normfinder)
ForegåendeNæste
- Undersøg, om det kan antages, at variansen af logaritmen til ekspressionsniveauet er den samme for de fire gener.