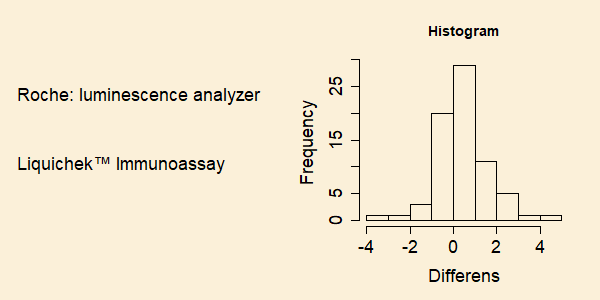
I et laboratorie skal man løbende kvalitetssikre måleinstrumenterne.
I artiken
The application of Student’s t-test in internal quality control of clinical laboratory
har man to måleinstrumenter fra Roche og standardprøver fra
firmaet Liquichek. Som en del af undersøgelsen ser man på differensen
mellem de målte værdier på de to apparater, idet enhver prøve deles
i to, og der måles på begge apparater.
Figuren nedenfor viser et histogram for 72 differenser
af målingen af indholdet af
luteotropic hormone.
Enheden er mIU/mL.
Der er flere ting at bemærke her. Data er kontinuerte i den forstand,
at den målte differens kan antage alle mulige værdier.
Den tilhørende stokastiske variabel beskrives gennem en tæthed,
der kan fortolkes som sandsynlighed per længde. Vi kan
tænke på de 72 målinger som et udsnit af en underliggende uendelig
stor population af differenser, og det er denne population, vi ønsker at
sige noget om ud fra de målte værdier i eksperimentet. Vores øjne
vil automatisk ud fra histogrammet danne sig et billede af et
centrum for fordelingen og et billede af, hvor stort et område målingerne
spreder sig over. I forhold til den underliggende population
svarer dette til middelværdi og spredning af fordelingen af differensen.
Det er naturligt at spørge, om middelværdien er nul svarende til, at
der ikke er systematisk forskel mellem de to måleapparater.
Ligesom vi i afsnit
1.1 så på, hvor langt det observerede
lå fra det forventede, vil det være oplagt her at se på, hvor langt
gennemsnittet af målingerne ligger fra den forventede værdi nul.
Her løber vi dog ind i et problem. Sandsynligheden for at få noget,
der ligger længere væk fra det forventede end det observerede gennemsnit,
vil afhænge af spredningen i populationen.
I dette kapitel indfører jeg det nok mest udbredte statistiske test, nemlig
-testet (Students
-test). Testet tager hensyn til den
ukendte spredning i populationen ved at standardisere afstanden mellem
gennemsnit og den forventede værdi med en spredning beregnet ud fra
målingerne. Testet indføres i afsnit
3.4. Testet tager
udgangspunkt i en antagelse om, at data følger en normalfordeling. Afsnit
3.1 repeterer meget kort jeres viden om normalfordelingen
fra jeres calculuskursus, og afsnit
3.2 giver en grafisk
metode til at vurdere, om data kan beskrives med en normalfordeling.
Det er en empirisk kendsgerning, at mange data kan beskrives med en
normalfordelingsmodel, og kapitlerne 4 til 7 i bogen her omhandler forskellige
modeller for normalfordelte data.
Et teoretisk argument for, at data ofte kan beskrives med en normalfordeling,
kan findes i den
centrale grænseværdisætning (afsnit
1.11),
der siger, at
hvis en stokastisk variabel kan tænkes på som fremkommet som en
sum af mange små bidrag, så vil fordelingen ligne en normalfordeling.
I den første del af dette kapitel betragtes
den grundliggende model med
n gruppe af
observationer, svarende til
eksemplet ovenfor med differens mellem to målinger.
Modellen analyseres i afsnit
3.3, og
analyse af data ved brug af Python beskrives i afsnit
3.7.
I kapitel
4
udvides modellen fra dette kapitel til situationen, hvor
vi har to grupper af observationer og ønsker at sammenligne
middelværdierne i de to underliggende populationer.
Ovenfor har jeg fokuseret på at uddrage viden fra data om middelværdien
i populationen. Spredningen kan dog også være af interesse, og
inferens om denne er beskrevet i afsnit
3.6.
I den anden del af kapitel 3 omtales
ophobningsloven og
afsnit
3.9 giver en introduktion til emnet.
ForegåendeNæste