Afsnit 9.4: Forward selektion
Definition 9.4.1.
(Forward selektion)
Et trin i forward selektionsalgoritmen kan beskrives på følgende vis.
Antag, at den nuværende model har inkluderet variablene
(ved start af algoritmen er ).
For hver variabel blandt de variable der endnu ikke er inkluderet,
prøver vi at udvide modellen med denne variabel. Dette giver en
model med variable, og for hvert kan vi beregne et
spredningsskøn, som vi kalder Den variabel med mindst
spredningsskøn er vores kandidat til udvidelsen af modellen. I modellen hvor variabel er inkluderet, kan vi se på -værdien
for test af hypotesen det vil sige, et test for at den sidst
inkluderede variabel kan undværes i modellen med variable.
Alt efter størrelsen på denne -værdi kan vi vælge at stoppe algoritmen.
I denne bog vil jeg ikke stoppe algoritmen ud fra -værdien, men ud fra
prædiktionsspredningen opnået ved cross-validation.Definition 9.4.2.
(Forward selektion med cross-validation)
Prædiktionsspredningen i en model, der inkluderer variable, findes ved,
at der i hvert trin af LOOCV proceduren laves en model med
variable fundet ved forward selektion.
Antallet af variable i slutmodellen findes
som den værdi af hvor prædiktionsspredningen (9.3.2) er mindst.
Lad os vende tilbage til data omkring oktantallet for 60
bensinprøver i afsnit 9.3. Tabellen nedenfor
viser i de tre første rækker resultatet af at bruge forward selektion,
indtil 6
variable er inkluderet. Den sidste række viser prædiktionsspredningen som
funktion af, hvor mange variable der inkluderes.
Den første variabel, der inkluderes, er variabel nummer 155.
Skønnet over spredningen i en regressionsmodel med kun
denne ene variabel er 0.661, og hvis vi i denne model laver
-testet for hypotesen er -værdien
Når vi går fra denne ene variabel
til to variable, er det variabel nummer 149, der tilføjes,
og spredningsskønnet falder fra 0.661 til 0.276. Dette
er et stort fald, og tilsvarende er -værdien for test af
hypotesen meget lille, nemlig
I næste trin inddrages variabel nummer 39, og den
tilsvarende -værdi er 0.0000056, og i fjerde trin kommer
variabel nummer 397 med, hvor -værdien er 0.0006.
I det femte trin
tilføjes variabel 36, men nu er -værdien noget større
nemlig 0.0245, og faldet i spredningsskøn er da også kun fra
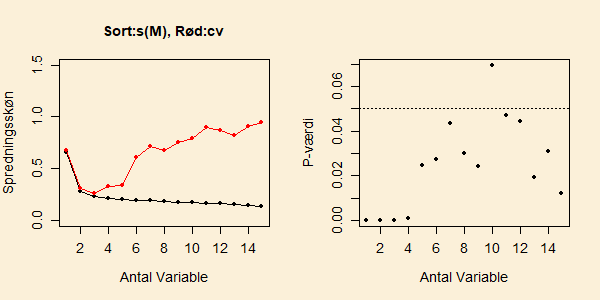
0.210 til 0.202. Figuren nedenfor viser tallene i tabellen
udvidet op til forward selektion med 15 variable.
Den sorte kurve i det venstre delplot er spredningsskønnet,
og det højre delplot viser p-værdierne. Vi ser tydeligt et
spring opad i -værdierne, efter at fire variable er inkluderet.
Fra 5 til 9 variable svinger -værdien mellem to og fem procent,
og det er først, når den tiende variabel inkluderes, at vi kommer over
en formel grænse på 5 procent.
9.4.1 Beregning i python
9.4.3 Forward selektion og cross-validation
I kodevinduet nedenfor hentes datasættet omkring oktantallet i
bensinprøver fra en GitHub-adresse.
Kør koden, og se, at output fra de 6 første variable stemmer
overens med tallene i tabellen ovenfor, og
at alle -værdierne stemmer overens med det højre delplot i
figuren ovenfor. Ændr dernæst funktionskaldet forward(spek,oktan,15) til
cvForward(spek,oktan,2), for at finde prædiktionsspredningen
ved forward selektion når der medtages fra 1 eller 2 variable.
Tjek, at de fundne værdier stemmer overens
med den røde kurve i ovenstående figur. I kodevinduet her er der en
timeout på beregningstiden på cirka 1 minut, hvorefter
processen stopper. Kør på jeres egen computer kommandoen
cvForward(spek,oktan,4).
Det næste skjulte punkt viser, hvordan vi kan bruge modellen fundet ved
forward selektion til at prædiktere nye prøver. Denne del kræver, at
vi indskriver de variable, vi har fundet ved forward algoritmen.
Åbn nu opstartskoden for at se definitionen på de to funktioner
forward og cvForward.
Her følger først lidt forklaring til koden i forward.
Det essentielle trin i beregningen er "for"-løkken inde i
forward-funktionen. Her prøver man for alle de
forklarende variable, der endnu ikke er med i modellen, at tilføje
en af disse () og beregne spredningskønnet når
variablen er tilføjet de allerede udvalgte variable (som der er af).
I den efterfølgende kommando argmin(res)
finder man nummeret på den variabel, der giver den mindste værdi
af Estimation af den multiple regressionsmodel foregår
ikke her med ols, som I ellers er vant til, men med
funktionen OLS. I den sidste er input ikke en modelformel,
men derimod en matrice med værdierne af de forklarende variable.
Efter at den nye variabel er fundet, estimeres den
multiple regressionsmodel, og -værdier findes i output. Lad os dernæst se på opbygningen af
funktionen cvForward.
I denne indeholder matricen sqFejl alle
de kvadrerede prædiktionsfejl, rækker svarer til observationsnummer
og søjle angiver, hvor mange led der tages med i forward selektion.
"For-løkken" over er selve cross-validation skridtet, hvor den
'te observation tages ud, og træningssættet består af de
resterende observationer. For hvert træningssæt gennemføres
forward selektion, og hver gang en ny variabel er tilføjet,
beregnes den prædikterede værdi for den observation, der er udeladt
af træningssættet.
9.4.4 Bruge slutmodellen til prædiktion
Når vi har gennemført en forward selektionsproces, og endt med at tage
variable med, ønsker vi at bruge en multipel regressionsmodel,
baseret på disse variable, til at lave prædiktion for kommende datasæt. Umiddelbart vil vi nok gribe dette an som beskrevet i det skjulte punkt
Konfidensinterval og prædiktionsinterval. Dog må
vi forvente, at de konfidensintervaller og prædiktionsintervaller,
der beregnes, er for smalle. Dette skyldes, at disse intervaller er på
formen
Per konstruktion af modellen vil vi forvente, at kan være for lille,
og en mulighed vil være at skifte denne ud med prædiktionsspredningen
I koden nedenfor er vist, hvordan dette kan gennemføres,
idet prædiktionsspredningen er kendt fra opbygningen af
modellen. For at illustrere dette vil jeg betragte den multiple
regressionsmodel med de tre forklarende variable nummer 155, 149 og 39
fundet ved forward selektion ovenfor. For at kunne lave prædiktion på
en ny prøve vil jeg kun bruge prøverne 1-59 i estimationen af modellen,
og bruge prøve nummer 60 til prædiktion. Kør koden. Kan du forstå længden af prædiktionsintervallet set i relation til
prædiktionsspredningen fra cross-validation ?
Prøv også at lave konfidensintervaller for middelværdien af kommende
observationer. Synes du, at modellen til beskrivelse af oktantallet er god nok i
forhold til at prediktere oktantallet for nye prøver ?
ForegåendeNæste