Afsnit 1.9: Konfidensinterval
Definition 1.9.1.
(95%-Konfidensinterval)
Betragt en statistisk model, hvor vi måler en stokastisk variabel
og hvor fordelingen af afhænger af parameteren
For hver mulig værdi af laves et interval
Vi betragter nu det
stokastiske interval og forlanger, at
sandsynligheden for at intervallet indeholder den sande værdi
af parameteren er 0.95. Når dette er opfyldt, kaldes intervallet et
95%-konfidensinterval. Skrevet op som en formel, er betingelsen
Hvis vi for eksempel i stedet ønsker et 90%-konfidensinterval, skal 0.95
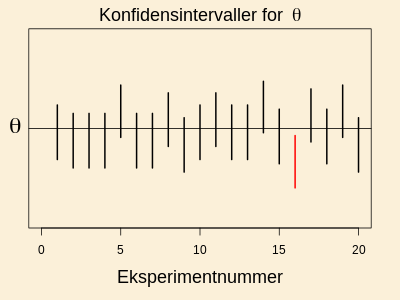
i ovenstående definition ændres til 0.90. Figuren nedenfor viser på
generisk form ideen i et konfidensinterval: et eksperiment er gentaget
20 gange, og hver gang er der lavet et konfidensinterval for
parameteren 19 ud af 20 gange (95%) indeholder intervallet den
sande værdi af parameteren. Konfidensintervallerne er vist som
lodrette linjestykker i figuren.
1.9.1 Konfidensinterval i binomialmodellen
Resultat 1.9.2.
(Konfidensinterval i binomialmodellen)
For modellen er et approksimativt
95%-konfidensinterval for baseret på observationen
givet ved
Hvis værdien af ændres til 1.645 får man i stedet et
approksimativt 90%-konfidensinterval.Eksempel 1.9.3.
(Rygerklassifikation ud fra fingeraftryk)
I Eksempel 1.8.3
omkring rygerklassifikation baseret på fingeraftryk
har vi og en måling
I kodevinduet nedenfor udregnes
det approksimative 95%-konfidensinterval. Resultatet
viser, at med "95% sikkerhed" er den sande værdi af sandsynligheden
for korrekt klassifikation et sted mellem 0.66 og 0.91. Hvis
sandsynligheden er helt nede på 0.66, giver klassifikationsreglen
kun det rigtige svar i 2 ud af 3 tilfælde. Udtrykket "95% sikkerhed" er blot en
omformulering af, at hvis formlen for dette konfidensinterval bruges
mange gange, så
vil vi i 95% af gangene have, at intervallet indeholder
den sande værdi af .
1.9.4 Beregning i Python af konfidensinterval for andel
Den følgende kode kan bruges generelt til beregning af konfidensintervallet
for en andel, hvis man selv indskriver det observerede antal () og
antal forsøg ().
Det næste kodevindue viser likelihoodfunktionen med konfidensintervallet
indtegnet (rødt interval) og intervallet, hvor likelihoodfunktionens
værdi er over (blåt interval). Figuren viser, at
de to intervaller er tæt på at være ens.
Prøv at lege lidt med koden for at få en fornemmelse
for bredden af konfidensintervallet. Prøv for eksempel
med og og prøv med det samlede resultat af
Kipping og Popes 46 deleksperimenter
fra afsnit 1.1.
Test dig selv: Konfidensinterval
Quiz
Betragt den statistiske model og et
95%-konfidensinterval for sandsynlighedsparameteren
Marker de korrekte udsagn.
Jeg er sikker på, at den sande værdi af parameteren ligger i
intervallet.
Hver gang jeg gentager eksperimentet, vil jeg få et nyt interval.
Ved uafhængige gentagelser vil intervallet indeholde den sande værdi
af parameteren i 95% af tilfældene.
Ved gentagelser er intervallet fast, men jeg får en ny værdi af
hver gang.
Konfidensinterval og $p$-værdi: sammenhæng
I ord er meningen med et konfidensintervallet at angive
de værdier af parameteren, der
virker rimelige til beskrivelse af data. Denne formulering er tæt på
at sige, at intervallet giver de værdier, vi kan acceptere, hvis vi
laver et formelt test. Mere præcist kan man sige, at hvis vi for hver værdi
af parameteren betragter hypotesen
og laver et test med tilhørende -værdi
så kan man lave et 95%-konfidensinterval bestående af alle
de værdier af for hvilke
At dette giver et konfidensinterval følger af resultatet
for fejl af type I nævnt i underafsnit 1.3.1
(giver at konfidensintervallet indeholder den
sande værdi af parameteren med sandsynlighed større end eller lig
med ).
Omvendt kan man så afgøre, om værdien er større end 0.05 ved at se,
om parameterværdien ligger i konfidensintervallet. Man kan dog lave forskellige udgaver af konfidensintervaller og af sine
tests. For de fleste situationer vi betragter i denne bog, hører test og
konfidensinterval sammen som beskrevet ovenfor. Dog gælder dette ikke
fuldstændig for binomialmodellen.
Testet i Resultat 1.2.3
er baseret på eksakte
sandsynligheder i binomialfordelingen, hvorimod
konfidensintervallet 1.9.2
er baseret på en approksimation. I praksis har dette ikke
nogen væsentligt betydning.