Afsnit 5.8: Øvelse 3
I artiklen
Ultrasmooth gold surfaces prepared by chemical mechanical polishing for applications in Nanoscience
beskrives en ny måde at lave meget
glatte overflader. Ruheden af en
overflade måles på AFM billeder (atomic force microscopy) og måles i
nanometer.
Der er målinger på 60 overflader (data i opgaven her er baseret på
figur 2 i artiklen). Data ligger i filen
Guldoverflade.txt.De 60 målinger af ruheden er fremkommet ved, at der på 5 wafers er udvalgt
12 områder, hvor ruheden er målt. En enkelt måling består i, at et
stort område betragtes via atomic force microscopy.
Indenfor dette område måles overfladens højde i nanometer
i et stort antal punkter, og den empiriske spredning af disse
højder beregnes og kaldes ruheden.
I denne opgave skal I angive den viden, vi har ud fra de 60 målinger
om overfladeruheden ved den anvendte produktionsproces.
Middelværdien siger noget om, hvilken ruhed processen generelt
producerer, og spredningen siger noget
om stabiliteten i processen. Artiklen, hvor data stammer fra,
vedrører en ny måde (chemical mechanical polishing) at producere
overflader på. Den tidligere anvendte metode (template stripped)
giver ifølge forfatterne en ruhed på 0.37 nm. Denne opgave kan formuleres kort som følger. Opstil en
statistisk model for ruheden,
lav inferens for parametrene i modellen,
og overvej om den nye produktionsmåde giver ruheder sammenlignelige med den
tidligere metode.
Skrevet ud bliver dette til følgende spørgsmål.
- Indlæs data fra filen Guldoverflade.txt. Lav et normal-qqplot af data og kommenter på figuren.Angiv andenkoordinaten, med to decimaler, til det anden-øverste punkt
- Opskriv en statistisk model for data.
- Angiv skøn og 95%-konfidensinterval for middelværdien af ruheden. Angiv resultat fra bogen til konstruktion af konfidensintervallet.
- Angiv skøn og 95%-konfidensinterval for spredningen af ruheden. Angiv resultat fra bogen til konstruktion af konfidensintervallet.
- Angiv -værdien for et test af hypotesen, at middelværdien af ruheden er 0.37, svarende til template stripped-metoden. Hvilken fordeling bruges til at finde -værdien ?
- I et normal-qqplot vil punktet yderst til venstre altid have den største andenkoordinat.
- Hvis gennemsnittet af observationer afviger mere end 2 fra , hvor vi ønsker at teste hypotesen, at middelværdien er , så vil vi altid forkaste hypotesen.
- For data i denne opgave kan vi acceptere hypotesen, at middelværdien er 0.39.
- Antallet af frihedsgrader i -fordelingen, der anvendes til test af, at middelværdien har en bestemt værdi, er generelt , hvor er antallet af observationer.
I artiklen
Spatial-temporal modeling of background radiation using mobile sensor networks
studeres baggrundsstrålingens variation over tid og sted.
Forfatterne motiverer studiet med følgende sætning:
"Modeling of background radiation for the urban environment plays an
important role in homeland security. However, background radiation is
difficult to assess due to its spatial-temporal fluctuations caused by
the variation in soil composition, building materials, and weather
patterns etc. To address the challenge of background radiation modeling,
we developed a mobile sensor network to continuously monitor the
background radiation."Som en del af undersøgelsen studeres
validiteten af den tidslige variation.
To detektorer er placeret på toppen af to bygninger med en afstand af
cirka 300 m. Enheden for målingerne er cps (counts per second), og
her i opgaven skal I se på 100 tilfældigt udvalgte måletidspunkter ud af en
tidsrække med op mod to millioner målinger. Data er i filen
TwoBackground.csv, der har tre søjler med overskrifterne
Tidspunkt, Detektor1 og Detektor2.
- Indlæs data, og dan to vektorer med målingerne fra de to detektorer, se eventuelt det skjulte punkt omkring indlæsning i afsnit 1.6. Lav en figur, hvor den målte værdi fra detektor 2 tegnes op mod værdien fra detektor 1 (detektor 1 værdierne skal være ud af førsteaksen og detektor 2 værdierne op langs andenaksen). Indtegn en passende linje med hældning 1 i figuren (afsnit Py.2.4). Kommenter på, hvad figuren viser.
- Dan nu en vektor med differenserne bestående af den målte værdi fra detektor 2 minus den målte værdi fra detektor 1. Lav et normal qqplot af differenserne, og opskriv en statistisk model for disse. Prøv også at lave et qqplot af værdierne for detektor 1 for at se, at disse er langt fra at være normalfordelte.
- Lav et test for hypotesen, at middelværdien af differensen er nul, svarende til hypotesen, at der ikke er forskel mellem de to detektorer. Lav dernæst et 95%-konfidensinterval for middelværdien af differensen. Diskuter med dine medstuderende, hvad der kan være årsag til forskel mellem de to detektorer.
I opgave 2.6 lavede I et eksakt
95%-konfidensinterval for forholdet
mellem to rater i poissonfordelingen. I skal
I denne opgave lave et approksimativt konfidensinterval baseret på
ophobningsloven. Data er tælletal for to områder af et spektrum,
et baggrundsområde og et formodet signalområde. Formålet
med undersøgelsen er at afgøre om der i signalområdet er en større
rate af hændelser end i baggrundsområdet.
Følgende tabel gengiver data fra opgave 2.6.
- Eftervis skøn og standard error for data fra baggrund.
- Beregn skøn for forholdet med de målte værdier i tabellen ovenfor.
- Vis, at de partielt afledede af funktionen udregnet i er
- Beregn standard error for skøn over forholdet med de målte værdier i tabellen ovenfor, og under antagelsen at de målte værdier er stokastisk uafhængige. Angiv Resultat fra webbogen der bruges.
- Beregn et approksimativt 95%-konfidensinterval for forholdet . Angiv Resultat fra webbogen der bruges. Sammenlign det approksimative konfidensinterval her med det eksakte konfidensinterval fra opgave 2.6.
- Ophobningsloven kan for eksemplet i denne opgave skrives som under antagelsen om, at de målte værdier af og er stokastisk uafhængige. Kan du eftervise denne formel ?
Den følgende tabel giver målte værdier af parametrene og
og tilhørende standard errors. De to målinger er stokastisk uafhængige.
Betragt funktionen og parameteren
Nedenfor er der 1 eller 2 korrekte svar. Find disse.
- Et approksimativt 68%-konfidensinterval for kan skrives som
- Da den afledede af funktionen med hensyn til er negativ kan vi ikke bruge ophobningsloven.
- Det approksimative 95%-konfidensinterval for er lige langt på begge sider af
- Data strider ikke mod hypotesen
- Hvis data er af dårlig kvalitet kan standard error for blive negativ.
Opgave 3.5: Ophobningslov med korrelation
Betydningen af nanopartikler i naturen diskuteres ofte.
En måde at måle betydningen på er ved kontrollerede eksperimenter,
hvor dødeligheden af for eksempel embryoer af zebrafisk
undersøges, når disse opholder sig i en opløsning med nanopartikler.
Som måleenhed for dødeligheden bruger man parameteren
(lethal concentration),
som er den log-koncentration, hvorunder 50% af embryoerne ikke overlever
at opholde sig i opløsningen i et fast tidsrum. I tabellen nedenfor er resultaterne fra figur 4 i artiklen
Comparative metal oxide nanoparticle toxicity using embryonic zebrafish.
For hver af 7 koncentrationer (Zn Ion Equivalent) af nanopartikler
er der registreret, hvor mange ud af 32 embryoer der dør.
For data i denne tabel er det naturligt at bruge modellen
hvor er det stokastiske antal døde blandt embryoer ved koncentration
nummer .
Hvis angiver logaritmen til den 'te koncentration, bruges ofte den
logistiske regressionsmodel, der er på formen
Modellen har således to parametre og , og i denne model er
givet ved .
Figuren nedenfor viser fraktionen af døde, det vil sige ,
afsat mod log koncentration . Endvidere er den estimerede logistiske kurve
indtegnet, det vil sige kurven med
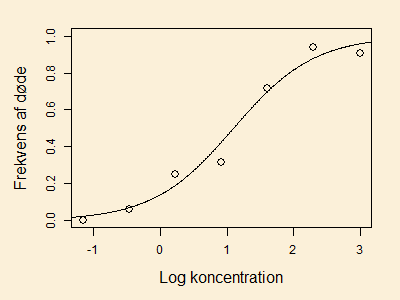 En analyse af data giver følgende parameterskøn og standard errors:
En analyse af data giver følgende parameterskøn og standard errors:
- Beregn skønnet over lethal concentration.
- Vis, at de partielt afledede af , udregnet i er Find standard error ud fra ophobningsloven.
- Lav et approksimativt 95%-konfidensinterval for . Virker det fundne interval rimeligt, i forhold til hvad I kan se i figuren ovenfor ?
Opgave 3.6: Ophobningsloven via simulering
I denne opgave fortsætter vi med bestemmelsen af forholdet mellem
to poissonrater i opgave 3.3 ovenfor. I denne opgave skal I forbedre
det approksimative konfidensinterval fra ophobningsloven ved hjælp af
simulationer som i eksemplet med gaskonstanten i afsnit 5.6.
I skal bruge koden fra sidst i afsnit 5.5, idet I skifter
de eksempelspecifikke dele ud. Forholdet findes ud fra formlen Da
indgår i nævneren, skal I i simulationen lade denne
variabel være nedadtil begrænset. De partielt afledede af er
- Betragt koden fra sidst i afsnit 5.5 og benyt rækkefølgen for de variable der indgår i forholdet Se på den første eksempelspecifikke del. Forklar at posList skal være på formen Indsæt i muhat, og indsæt standard errors i stds.Indsæt under thetahat formlen nu udtrykt ved muhat, hvor første indgang er og den anden indgang er Indsæt på tilsvarende måde under dthetaDmu formlerne for de partielle afledede af forholdet udtrykt ved muhat.
- Betragt dernæst den anden eksempelspecifikke del. Indsæt under thetatilde formlen for forholdet, nu udtrykt ved søjlerne i muSim, hvor første søjle er simulerede målinger af og den anden søjle er simulerede målinger af Indsæt på tilsvarende måde under dtildeDmu formlerne for de partielle afledede af forholdet udtrykt ved søjlerne i muSim.
- Kør programmet og diskuter forholdet mellem det approksimative konfidensinterval beregnet i opgave 3.3 og det simulationsbaserede interval.
- I programmet udskrives det simulationsbaserede skøn over standard error, Synes I, at spredningskønnet fra ophobningsloven i opgave 3.3 er tilfredsstillende i dette eksempel ?
Opgave 3.7: Afleveringsopgave 2
I forbindelse med besvarelsen af denne opgave skal du downloade
filen svarAflevering2.txt fra kursushjemmesiden og indsætte nogle tal
fra din besvarelse som angivet nedenfor. Filen skal afleveres
sammen med din pdf-fil med besvarelsen.I opgave 1.5 betragtede I data fra et eksperiment
delt op i fire dele.
For at bekræfte/afkræfte en teori indenfor kvantefysik skulle man se på om
gennemsnittet af fire sandsynligheder,
var under en teoretisk beregnet værdi på
0.0183. Data fra artiklen består af skøn og standard errors for de fire
sandsynligheder. Resultaterne er gengivet i følgende tabel.
Data fra denne tabel er brugt til at beregne data i tabellen i
opgave 1.5.
- Beregn et skøn over gennemsnitssandsynligheden Overfør den fundne værdi, med fire decimaler, til svarAflevering2.txt.
- Find de partielle afledede af gennemsnitssandsynligheden med hensyn til og
- Benyt ophobningsloven til at beregne standard error for skønnet over gennemsnitssandsynligheden Angiv Resultat fra webbog til beregning af standard error. Ovefør både standard error, med fire decimaler, og Resultat nummer til svarAflevering2.txt.
- Beregn et approksimativt 95%-konfidensinterval for gennemsnitssandsynligheden ud fra ophobningsloven. Overfør den øvre grænse i konfidensintervallet, med fire decimaler, til svarAflevering2.txt.
- Betragt en normalfordeling med middelværdi 0.0183 og med spredning givet ved standard error for og beregn sandsynligheden for et udfald mindre end eller lig med Kommenter på den fundne sandsynlighed i forhold til udsagnet "Within experimental error, the results confirm quantum theory."
Betragt binomialmodellen og skønnet
over parameteren . Der gælder
(skal ikke vises) at standard error for er
- Benyt ophobningsloven til at lave et approksimativt 95%-konfidensinterval for parameteren ( kaldes log-odds) i situationen med og
Denne opgave knytter an til den foregående opgave.
Betragt to uafhængige binomialmodeller
Odds i den første model er og odds i den anden model
er Oddsratio (OR) defineres som
Log-oddsratio (logOR) er derfor
Skøn over denne, fås ved at indsætte skøn
over og skøn over
- Benyt ophobningsloven til at finde standard error for under benyttelse af (5.8.2).
- Lav et approksimativt 95%-konfidensinterval for log-oddsratio med følgende data
Opgave 3.10: Histogram med tæthed indtegnet
Betragt igen data fra opgave 3.1 med ruheden af 60 overflader.
- Lav et tæthedshistogram af data.
- Indtegn i histogrammet tætheden for en normalfordeling med middelværdi 0.3972 og spredning 0.04667 (se eventuelt koden i afsnit 3.5).
Opgave 3.11: Logaritmetransformation
Betragt igen data fra opgave 3.1 med ruheden af 60 overflader.
- Overvej, om du vil beskrive ruheden med en normalfordeling, eller om du vil beskrive logaritmen til ruheden med en normalfordeling.
Opgave 3.12: Prædiktion i logistisk regression
Betragt igen data fra opgave 3.5 beskrevet med den
logistiske regressionsmodel. Vi er særlig interesseret i situationen,
hvor logaritmen til dosis er .
- Benyt ophobningsloven til at lave et approksimativt 95%-konfidensinterval for parameteren
- Oversæt det fundne konfidensinterval til et konfidensinterval for sandsynligheden for at dø, det vil sige
- Benyt i stedet ophobningsloven til at lave et approksimativt 95%-konfidensinterval for
Opgave 3.13: Konfidensinterval for opsummerede data
I laboratoriet måles modstanden i en jerntråd af 5 studerende uafhængigt af
hinanden. Erfaringen viser, at sådanne målinger kan beskrives
med en normalfordeling.
Gennemsnit af de 5 målinger er 0.971 og den empiriske spredning
på de 5 målinger er 0.046
- Lav et 95%-konfidensinterval for middelværdien af modstanden i tråden.
Betragt -testet for test af hypotesen i normalfordelingsmodellen,
hvor den underliggende spredning er
I spørgsmålene nedenfor skal I se på styrken af testet ved hjælp af
kodevinduet i underafsnit 4.4.1.
I kodevinduet bruges som her i opgaven blot er
ForegåendeNæste
- Lad antallet af observationer være Find styrken af testet når den alternative værdi af er , eller
- Find værdien af således at styrken er mindst 0.9 under alternativet for og styrken er mindre end 0.9 for