Afsnit 7.8: Ikke-lineær regression
Formålet med dette afsnit er at gøre jer bekendt med den
statistiske model,
der ligger bag avancerede programmer i
python
til estimation af ikke-lineære sammenhænge, specifikt
pythons funktion
curvefit.
I skal ikke selv analysere data med disse programmer,
da dette ligger uden for indholdet i denne webbog.
I nogle situationer er en lineær funktion ikke tilstrækkelig til at
beskrive sammenhængen i data. Et eksempel er inden for studiet af
iontransport.
I artiklen
Unbiased Simulations Reveal the Inward-Facing
Conformation of the Human Serotonin Transporter and
Na+ Ion Release,
skrevet af forskere fra Aarhus Universitet,
omtales et eksperiment
med transport af Na+ i celler fra pattedyr. Forskellige
koncentrationer af NA+ er indsat i cellerne, og raten hvormed ionerne
transporteres måles. Der omtales to eksperimenter,
hvor der bruges forskellige proteiner til transport af Na+,
henholdsvis en vildtype
hSERT (human serotonin transporter) og en muteret type
Asp437Asn.
Koncentrationen måles i
mM og raten i
cpm (counts
per minute).
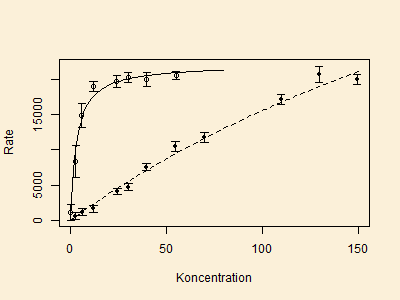
Data der anvendes nedenfor er aflæst fra figur 6 i artiklen og er
vist i nedenstående figuren.
Michaelis-Menten kinetik
forbinder en reaktionsrate
med koncentrationen
af et substrat gennem ligningen
Der er således to parametre i denne model. Parameteren
angiver den
maksimale reaktionsrate, og parameteren
angiver den koncentration,
under hvilken reaktionsraten vil være det halve af den maksimale
værdi
. Relationen
(7.8.1) med skønnede parameterværdier
er indtegnet i figuren nedenfor, hvor den venstre kurve er for
hSERT eksperimentet og den højre kurve er for Asp437Asn eksperimentet.
Den generelle model vi vil betragte beskriver den
ikke-lineære sammenhæng gennem parametre i vektoren
Typisk vil der også være en forklarende variabel
således at den
'te observation af respons er knyttet til værdien
af den forklarende variabel. Vi kan skrive dette generelt ved at lade
middelværdien af det
'te respons
være
.
Den lineære regressionsmodel vi har betragtet i dette kapitel svarer til
og Michaelis-Menten kinetik
omtalt ovenfor svarer til
Hvor vi i den lineære regressionsmodel forlanger at variansen af respons
er den samme for alle
vil vi her tillade at variansen skalerer
med kendte vægte,
, hvor
er
de kendte vægte. I ovenstående figur er vægtene
illustreret gennem en errorbar ved hvert målepunkt.
Som det sidste element i modellen siger vi at data
er normalfordelte.
Statistisk Model 7.8.1.
(Den ikke-lineære regressionsmodel i curvefit)
I den ikke-lineære regresisonsmodel har vi
funktioner
og
uafhængige stokastiske variable
med
Skøn over
findes ved
vægtet mindste kvadraters metode
svarende til at vi finder skønnet
ved at minimere
Når skønnet
er fundet bruger vi som skøn over
værdien
hvor
er antallet af parametre i
Der gælder approksimativt, at
hvor det sidste bruges til at lave et approksimativt 95%-konfidensinterval
på formen
Som en del af output fra curve
fit kan man få
en kovariansmatriks for
Dette er en
matriks, hvor det
'te diagonalelement er
og det
'te element er
Med denne matriks til rådighed
kan vi bruge ophobningsloven til beregning af usikkerheden på
afledede parametre. Formlen for matricen er
Som nævnt er fordelingsresultaterne (og konfidensintervallerne baseret på
disse) approksimative, og erfaringsmæssigt ved man, at
approksimationerne ikke altid er gode.
7.8.1 Kørsel af curvefit
Nedenfor analyseres de to datasæt vist i figuren tidligere i dette afsnit
omkring Michaelis-Menten kinetik. Modellen er således
hvor
er koncentrationen af Na+ ioner, og
er den målte
transportrate. Pythons funktion curve
fit
skal som input have en funktion, der definerer den ikke-lineære sammenhæng,
en vektor med værdierne af den forklarende variabel, en
vektor med responsværdierne, eventuelt en vektor med
vægte (tildeles
sigma), og eventuelt en vektor med startværdier
for søgning efter skøn over parametrene (tildeles
p0).
Ofte vil søgerutinen ikke kunne finde passende skøn over parametrene
medmindre den hjælpes på vej med startværdier.
Output fra curve
fit består af parameterskøn
(
popt i kode nedenfor) og kovariansmatriks beskrevet ovenfor
(
pcov i kode nedenfor).
Se opstartskoden (til/fra)
Kørsel af koden ovenfor giver følgende skøn og 95%-konfidensintervaller
for
og
.
For begge datasæt får vi et meget bredt konfidensinterval
(den øvre grænse er flere gange større end den nedre grænse).
For ASP datasættet (til højre i figur) er det tydeligt,
at forklaringen på dette er, at
vi ikke er i stand til at fastlægge den øvre grænse for raten,
og dermed kan vi ikke fastlægge hvilken koncentration, der giver
en rate, der er halvdelen af maksimum.
For hSert datasættet har vi god viden om den øvre grænse, men i det område
hvor raten cirka er halvdelen af den øvre grænse, er der stor
usikkerhed på ratemålingen, hvorfor vi har svært ved at fastlægge,
for hvilket koncentration raten er lig med halvdelen af den øvre grænse.
ForegåendeNæste